
이 도구의 기능
이 생성기는 여러분이 직접 지정한 평균과 표준편차를 가진 정규분포(가우스 분포)를 따르는 의사난수 목록을 만들어 줍니다. 균등분포 난수를 정규분포 난수로 변환하는 간단하면서도 정확한 고전적 기법인 Box-Muller 변환을 사용합니다. 결과물의 핵심은 N(μ, σ²)에서 추출된 값들을 쉼표로 구분한 목록입니다.
사용 방법
먼저 분포의 중심을 나타내는 평균(μ)과, 값들이 얼마나 넓게 퍼져 있는지를 결정하는 표준편차(σ)를 입력하세요. 그다음 생성할 난수의 개수(1~1000개)를 정하고, 유효숫자 단위로 표시 정밀도를 선택하면 됩니다. 매번 실행할 때마다 확률적으로 추출되므로, 제출할 때마다 완전히 새로운 난수 세트를 얻게 됩니다.
공식 살펴보기
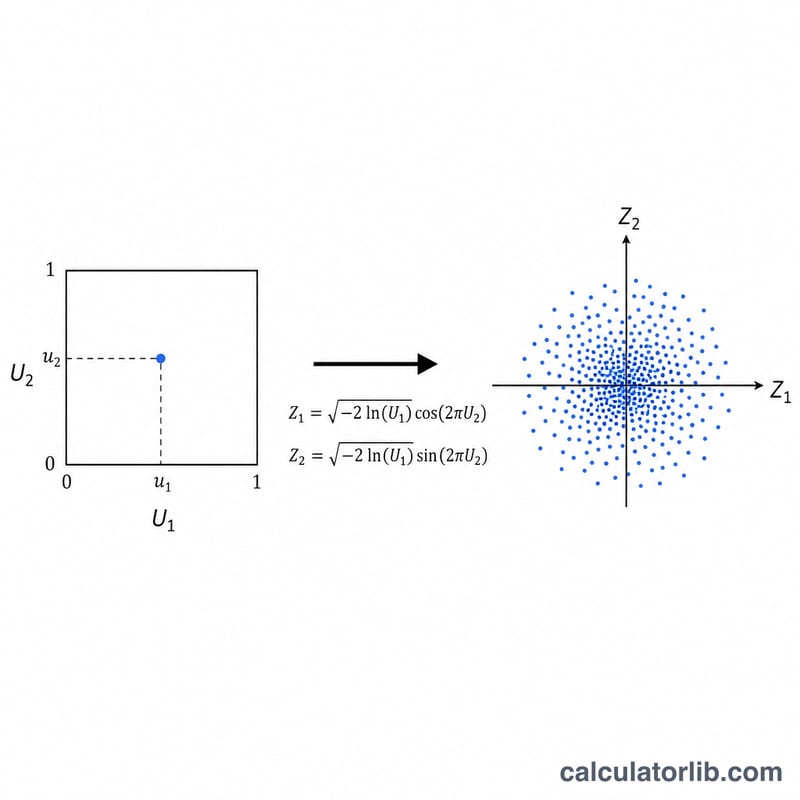
먼저 열린구간 (0,1)에서 서로 독립인 두 개의 균등 난수 U1과 U2를 뽑습니다. Box-Muller 변환은 이 두 값을 서로 독립인 두 개의 표준정규 난수로 바꿔 줍니다. Z1 = √(−2·ln U1)·cos(2πU2), Z2 = √(−2·ln U1)·sin(2πU2). 따라서 한 번 계산할 때마다 정규 난수 두 개가 동시에 나옵니다. 각 표준정규 값은 X = μ + σ·Z 로 다시 척도를 조정합니다. ln(0) = −∞ 가 되는 것을 막기 위해 U1이 정확히 0이 되지 않도록 보호 처리합니다.
계산 예시
μ = 100, σ = 15 라 하고, U1 = 0.5, U2 = 0.25 라고 가정해 봅시다. 그러면 √(−2·ln 0.5) = √1.386294 = 1.177410 입니다. cos(π/2) = 0, sin(π/2) = 1 이므로 Z1 = 0, Z2 = 1.177410 이 됩니다. 따라서 X1 = 100 + 15·0 = 100, X2 = 100 + 15·1.177410 = 117.66115 입니다. 이런 쌍을 많이 뽑을수록 표본 평균은 100에, 표본 표준편차는 15에 점점 가까워집니다.
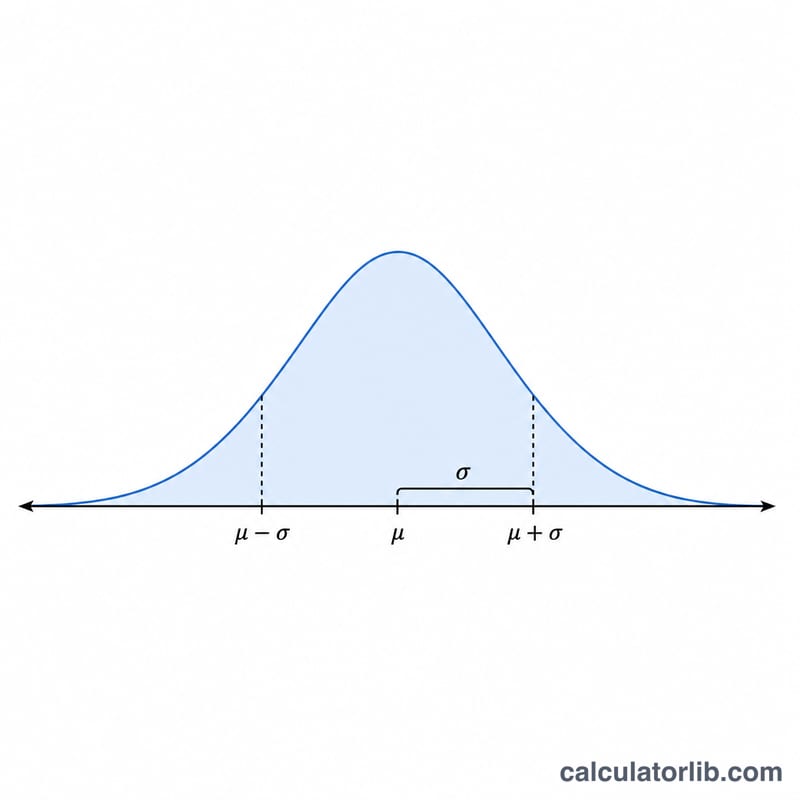
68-95-99.7 규칙 (경험적 규칙)
정규분포 \(N(\mu, \sigma^2)\)에서는 평균으로부터 정해진 개수의 표준편차 범위 내에 일정한 비율의 값들이 떨어집니다. 이것이 경험적 규칙이며, 여러분이 생성한 숫자들에 대한 유용한 확인 방법입니다. 충분히 큰 표본에서는 아래의 비율들이 자동으로 나타날 것입니다.
| 구간 | 값의 범위 | 구간 내 비율 | 꼬리 부분 비율 |
|---|---|---|---|
| \(\pm 1\sigma\) | \(\mu - \sigma\) ~ \(\mu + \sigma\) | 68.27% | 31.73% |
| \(\pm 2\sigma\) | \(\mu - 2\sigma\) ~ \(\mu + 2\sigma\) | 95.45% | 4.55% |
| \(\pm 3\sigma\) | \(\mu - 3\sigma\) ~ \(\mu + 3\sigma\) | 99.73% | 0.27% |
예제: \(\mu = 100\), \(\sigma = 15\)로 숫자를 생성하면, 약 68%의 값이 85에서 115 사이에, 약 95%가 70에서 130 사이에, 약 99.7%가 55에서 145 사이에 떨어질 것입니다. \(\pm 3\sigma\) 범위 밖의 값(여기서는 55 이하 또는 145 이상)은 1,000번의 추출 중 약 3번 정도만 나타날 것으로 예상됩니다.
생성된 숫자 해석하기
Box-Muller 변환은 선택한 평균 \(\mu\)를 중심으로 하고 표준편차 \(\sigma\)로 설정한 퍼짐을 따르는 정규(가우스) 분포 값들을 생성합니다. 이러한 사실들을 염두에 두고 읽으세요:
- 대부분의 값들은 평균 근처에 몰려있습니다. 종 모양은 \(\mu\)에서 가장 밀집하므로, 일반적인 추출값은 \(\mu\)에 가깝습니다. 대략 3분의 2 정도의 값들이 평균으로부터 한 \(\sigma\) 범위 내에 떨어집니다.
- 극단값은 드물지만 가능합니다. 꼬리 부분 먼곳의 값(예를 들어 \(3\sigma\) 범위 이상)은 보기 드물지만 불가능하지는 않습니다. 이런 값은 약 0.27%의 확률로 나타납니다. 가끔씩 이상값을 보는 것은 정상적인 동작이지, 오류가 아닙니다.
- 표본 통계량은 \(n\)이 증가함에 따라 수렴합니다. 작은 개수에서는 표본 평균과 표본 표준편차가 우연히 \(\mu\)와 \(\sigma\)와 눈에 띄게 다를 수 있습니다.
count를 증가시키면, 표본 평균은 \(\mu\)에 가까워지고 표본 표준편차는 \(\sigma\)에 가까워집니다(대수의 법칙). 배치를 표본 평균 계산기나 모집단 표준편차 계산기에 붙여 넣어 값들이 여러분의 목표값으로 수렴하는 것을 확인할 수 있습니다. - 이것은 시뮬레이션과 테스트용입니다. 이것들은 몬테카를로 실험, 부하/스트레스 테스트, 교육, 모델링을 위한 의사난수 추출이지, 어떤 실제 수량의 실측 데이터가 아닙니다. 이 숫자들은 여러분이 지정한 분포를 넘어 경험적 의미를 갖지 않습니다.
정의 & 용어집
- 평균 (\(\mu\))
- 분포의 중심 또는 기댓값으로, 생성된 값들이 균형을 이루는 중심 값입니다.
- 표준편차 (\(\sigma\))
- 데이터와 같은 단위로 측정한 퍼짐의 정도입니다. 더 큰 \(\sigma\)는 평균에서 더 멀리 퍼져있는 값들을 생성합니다.
- 분산 (\(\sigma^2\))
- 표준편차의 제곱 \(\sigma^2\)입니다. 제곱 단위에서 퍼짐을 정량화하며, 분포 표기법 \(N(\mu, \sigma^2)\)에 나타나는 모수입니다.
- 표준정규분포, \(N(0,1)\)
- 평균 0, 표준편차 1인 특별한 정규분포입니다. 이것에서 뽑은 임의의 값 \(Z\)는 \(X = \mu + \sigma Z\)를 통해 여러분의 분포로 재조정됩니다.
- 균등분포
- 구간(여기서는 \((0,1)\)) 내의 모든 값이 동일하게 가능한 분포입니다. Box-Muller 방법은 두 개의 독립적인 균등분포 추출 \(U_1\)과 \(U_2\)에서 시작합니다.
- Z-점수
- 값이 평균으로부터 떨어져 있는 표준편차의 부호가 있는 개수, \(Z = (X - \mu)/\sigma\)입니다. Z-점수 0은 정확히 평균에 위치하고, \(\pm 2\)는 중앙 95.45%의 경계를 표시합니다.
- 의사난수
- 난수의 통계적 성질을 가진 수열을 생성하는 결정론적 알고리즘으로 생성된 값입니다. 출력은 난수처럼 보이고 통계 검정을 통과하지만 같은 시드로부터 완전히 재현 가능합니다.
- Box-Muller 변환
- \(Z = \sqrt{-2\ln U_1}\,\cos(2\pi U_2)\)를 사용하여 두 개의 독립적인 균등난수 \(U_1, U_2\)를 표준정규값으로 변환한 뒤 요청된 평균과 표준편차로 이동 및 재조정하는 방법입니다.
자주 묻는 질문
실행할 때마다 숫자가 달라지는 이유는 무엇인가요? 이 생성기는 고정된 시드(seed) 없이 매번 새로운 균등 난수를 뽑기 때문에, 설계상 결과가 무작위로 나옵니다.
σ = 0 으로 설정하면 어떻게 되나요? 분포가 퇴화(degenerate)하여 생성되는 모든 값이 평균과 동일해집니다.
표본 평균이 μ와 정확히 일치하지 않는 이유는 무엇인가요? 무작위 추출에는 표본 오차가 따르기 때문입니다. 난수를 많이 생성할수록 표본 평균과 표준편차가 각각 μ와 σ에 더욱 가까워집니다.





