이 도구의 기능
이 생성기는 원하는 형상모수 a와 척도모수 b를 가진 감마분포를 따르는 의사난수 목록을 만들어 줍니다. 감마분포는 항상 양수 값만 갖는 연속분포로, 신뢰성 공학, 대기행렬 이론, 베이즈 통계(켤레 사전분포), 강우량·보험 모델링은 물론 대기 시간이나 양의 방향으로 치우친 값을 다루는 모든 분야에서 폭넓게 활용됩니다. 특정 국가에 국한되지 않는 보편적인 수학 도구입니다.
사용 방법
형상모수 a(0보다 커야 함), 척도모수 b(0보다 커야 함), 그리고 생성할 값의 개수(1~1000)를 입력하세요. 표시할 유효숫자 자릿수를 선택한 뒤 계산 버튼을 누르면 정렬된 난수 목록과 함께 표본평균·표본분산이 출력됩니다. 이론적 평균·분산도 나란히 표시되므로 결과가 타당한지 바로 확인할 수 있습니다.
공식
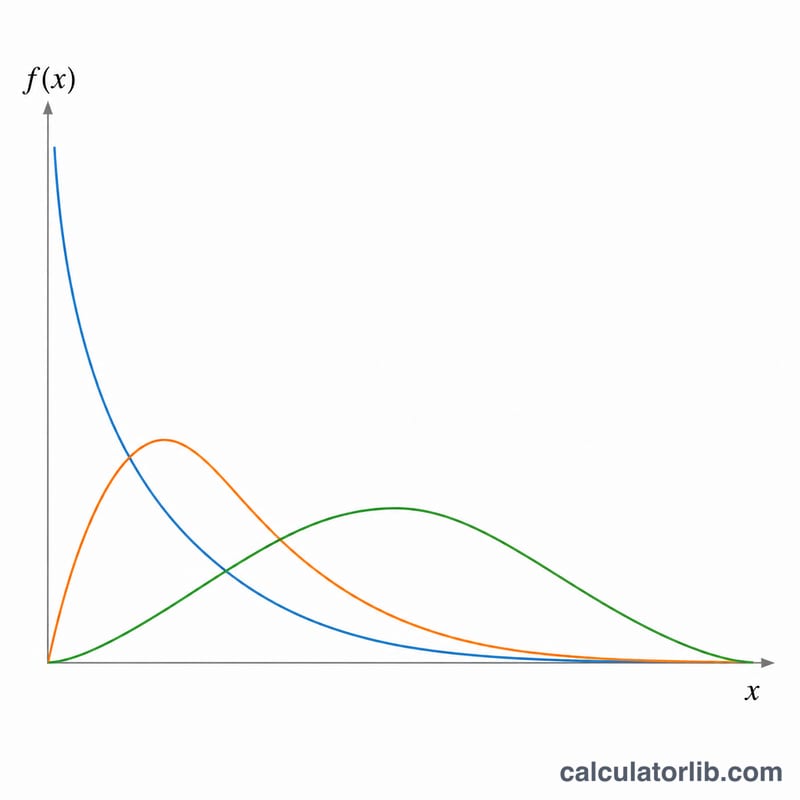
확률밀도함수는 \(x > 0\)일 때 다음과 같으며,
$$f(x; a, b) = \frac{1}{\Gamma(a)\cdot b} \cdot \left(\frac{x}{b}\right)^{a-1} \cdot e^{-x/b}$$여기서 \(\Gamma(a)\)는 감마함수입니다. 이 척도 매개변수화에서 평균은 \(a\cdot b\), 분산은 \(a\cdot b^2\)입니다. 여기서 \(b\)는 율(rate)이 아니라 척도(scale)임에 유의하세요. 다른 라이브러리에서 율 \(\lambda = 1/b\)를 사용한다면 \(b = 1/\lambda\)로 설정하면 됩니다. 표본 추출에는 \(a \ge 1\)일 때 Marsaglia-Tsang squeeze 기법을, \(a < 1\)일 때는 균등분포 거듭제곱 보정을 사용합니다. 단위 척도로 뽑은 각 값에 \(b\)를 곱해 척도를 반영합니다.
예제로 살펴보기
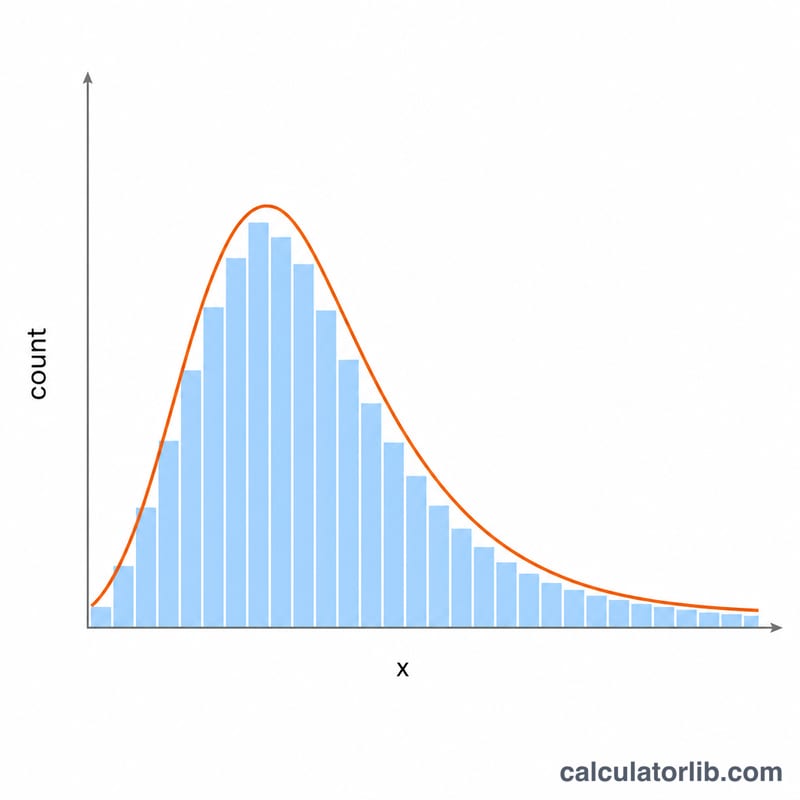
\(a = 3\), \(b = 1\), 개수 = 10으로 설정하면 모든 값이 Gamma(3,1) 표본이 됩니다. 이론적 평균은 \(a\cdot b = 3\), 이론적 분산은 \(a\cdot b^2 = 3\)(표준편차 \(\approx 1.732\))입니다. 실제로 뽑힌 값들은 평균이 3 근처에, 산포가 1.7 안팎에 형성될 가능성이 높습니다. \(a = 2\), \(b = 5\)로 바꾸면 평균은 10, 분산은 50이 되며, 값은 여전히 항상 양수로 유지됩니다.
자주 묻는 질문
실행할 때마다 숫자가 달라지는 이유는 무엇인가요? 결과가 난수이기 때문에 고정 시드를 사용하지 않는 한 매번 값이 달라집니다. 다만 표본평균과 표본분산은 이론값에 가깝게 유지되어야 합니다.
a = 1이면 어떻게 되나요? Gamma(1, b)는 평균이 \(b\)인 지수분포가 됩니다. \(a\)가 정수이면 얼랑(Erlang)분포가 됩니다.
b는 율인가요, 척도인가요? 척도입니다. 평균이 \(a\cdot b\)이므로, \(b\)가 커질수록 분포가 더 큰 값 쪽으로 늘어납니다.