Что такое предельная ошибка для доли?
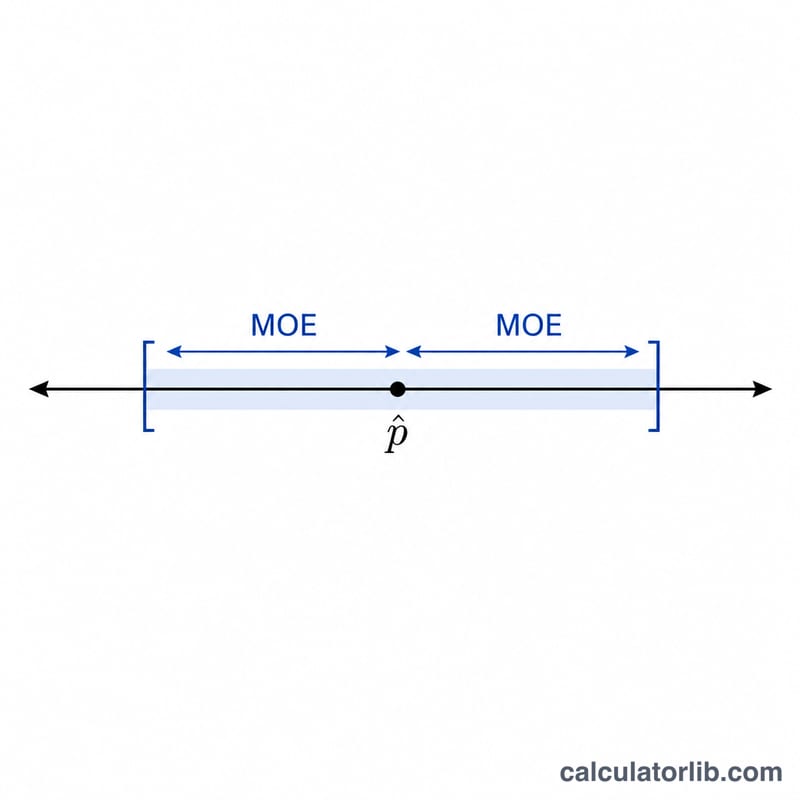
Предельная ошибка (MOE) показывает, насколько выборочная доля может отличаться от истинной доли во всей генеральной совокупности. Когда вы опрашиваете выборку и обнаруживаете, что доля \(\hat{p}\) респондентов выбирает определённый вариант, предельная ошибка задаёт интервал ± вокруг этой оценки при заданном уровне доверия. Калькулятор универсален — он подходит для любого опроса или соцопроса в любой стране.
Как пользоваться
Введите выборочную долю \(\hat{p}\) в виде десятичной дроби от 0 до 1 (например, 0,52 означает 52%), укажите объём выборки \(n\) и выберите уровень доверия (90%, 95% или 99%). Калькулятор покажет предельную ошибку в процентах, стандартную ошибку, использованное критическое значение \(z\) и итоговый доверительный интервал. Кроме того, он проверяет «правило пяти», чтобы вы понимали, корректно ли применять нормальное приближение.
Разбор формулы
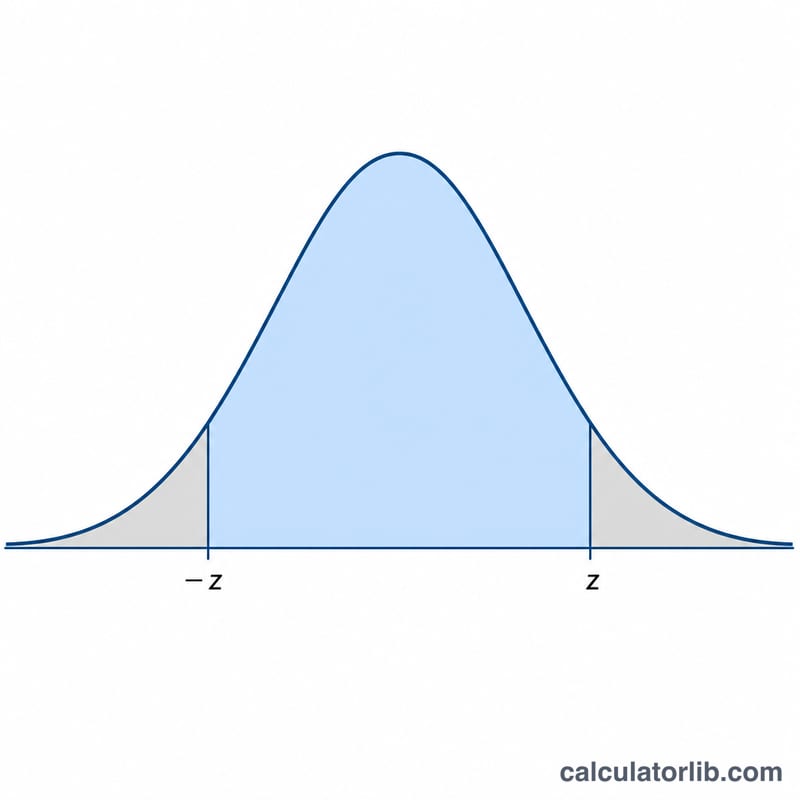
Предельная ошибка вычисляется как $$\text{MOE} = z \cdot \sqrt{\frac{\hat{p}\,(1-\hat{p})}{n}}$$ Выражение \(\sqrt{\hat{p}(1-\hat{p})/n}\) — это стандартная ошибка доли, и она уменьшается по мере роста объёма выборки \(n\). Значение \(z\) — критическое значение стандартного нормального распределения: 1,645 для 90%, 1,96 для 95% и 2,576 для 99% доверия. Умножая стандартную ошибку на \(z\), мы масштабируем интервал до нужного уровня уверенности.
Пример расчёта
Допустим, 52% из 1000 опрошенных избирателей поддерживают некую инициативу, то есть \(\hat{p} = 0{,}52\) и \(n = 1000\), при уровне доверия 95% (\(z = 1{,}96\)). Стандартная ошибка равна $$\sqrt{\frac{0{,}52 \cdot 0{,}48}{1000}} = \sqrt{0{,}0002496} \approx 0{,}0158$$ Предельная ошибка составляет $$1{,}96 \times 0{,}0158 \approx 0{,}0310$$ то есть около 3,1%. Доверительный интервал — 52% ± 3,1%, примерно от 48,9% до 55,1%.
Частые вопросы
Что такое правило пяти? Оно гласит, что нормальное приближение для доли надёжно, когда выполняются оба условия: \(n \cdot \hat{p} \geq 5\) и \(n \cdot (1-\hat{p}) \geq 5\). Если хотя бы одна величина меньше 5, используйте точный метод, например интервал Клоппера — Пирсона.
Почему при неизвестном значении берут \(\hat{p} = 0{,}5\)? Произведение \(\hat{p}(1-\hat{p})\) максимально именно при 0,5, что даёт самую консервативную (наиболее широкую) предельную ошибку. Это часто применяют при планировании объёма выборки.
Снижает ли увеличение выборки предельную ошибку? Да — поскольку \(n\) стоит в знаменателе под корнем, предельная ошибка уменьшается пропорционально \(1/\sqrt{n}\).