À quoi sert ce calculateur
Le test Z pour un échantillon permet de déterminer si la moyenne d'un échantillon s'écarte de façon significative d'une moyenne de population connue ou supposée. C'est le test approprié lorsque l'écart-type de la population (sigma) est connu. L'outil affiche la statistique de test \(z\), l'erreur standard, la valeur \(z\) critique au seuil de signification choisi, la p-valeur, ainsi qu'un verdict clair indiquant si l'écart est statistiquement significatif.
Comment l'utiliser
Saisissez le seuil de signification alpha en pourcentage (5 correspond à 0,05). Choisissez un test bilatéral (la moyenne de l'échantillon peut être supérieure ou inférieure) ou un test unilatéral (vous ne vous intéressez qu'à un seul sens). Indiquez ensuite la moyenne de population supposée (mu0), l'écart-type connu de la population (sigma), la moyenne observée de l'échantillon (x-barre) et la taille de l'échantillon (\(n\)). Cliquez sur calculer pour obtenir le résultat complet.
La formule expliquée
L'erreur standard vaut \(SE = \sigma / \sqrt{n}\). La statistique de test est $$z = \frac{\bar{x} - \mu_0}{\sigma / \sqrt{n}}$$ La valeur critique provient de l'inverse de la fonction de répartition normale centrée réduite : pour un test bilatéral \(z_{\text{crit}} = \Phi^{-1}(1 - \alpha/2)\) ; pour un test unilatéral \(z_{\text{crit}} = \Phi^{-1}(1 - \alpha)\). La p-valeur est égale à \(2(1 - \Phi(|z|))\) en bilatéral ou \(1 - \Phi(|z|)\) en unilatéral, où \(\Phi\) désigne la fonction de répartition de la loi normale centrée réduite. Le résultat est significatif (on rejette l'hypothèse nulle \(H_0 : \bar{x} = \mu_0\)) lorsque \(|z|\) dépasse \(z_{\text{crit}}\), c'est-à-dire lorsque \(p\) est inférieur à \(\alpha\).
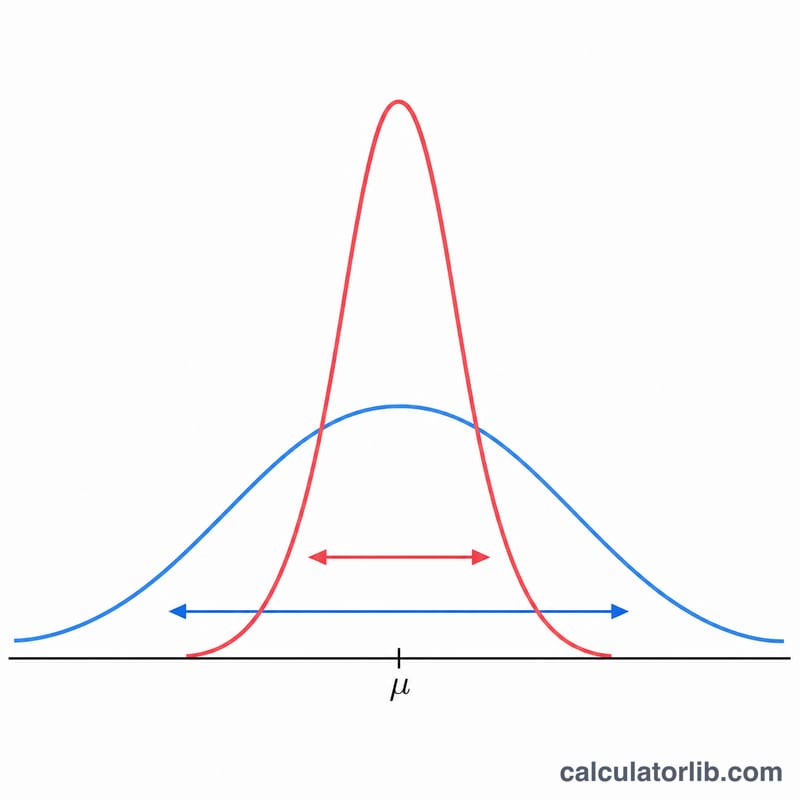
Exemple détaillé
Avec \(\mu_0 = 58\), \(\sigma = 4{,}5\), \(\bar{x} = 60\), \(n = 25\) et un test bilatéral au seuil \(\alpha = 5\,\%\) : $$SE = \frac{4{,}5}{\sqrt{25}} = 0{,}9$$ $$z = \frac{60 - 58}{0{,}9} = 2{,}2222$$ La valeur critique bilatérale \(\Phi^{-1}(0{,}975) = 1{,}95996\). Comme \(2{,}2222 > 1{,}95996\), l'écart est significatif. La p-valeur vaut \(2(1 - \Phi(2{,}2222)) = 0{,}0263\), soit moins de 0,05, ce qui confirme le résultat.
FAQ
Quand faut-il plutôt utiliser un test de Student (test t) ? Utilisez un test t lorsque seul l'écart-type de l'échantillon est connu (sigma de la population inconnu), notamment pour les petits échantillons ; il s'appuie sur la loi de Student à \(n-1\) degrés de liberté.
Que signifie la p-valeur ? C'est la probabilité d'observer un écart au moins aussi extrême que le vôtre si \(H_0\) était vraie. Une p-valeur faible (inférieure à \(\alpha\)) indique qu'il est peu probable que l'écart soit dû au hasard.
Bilatéral ou unilatéral ? Privilégiez le test bilatéral, sauf si vous avez une raison solide, fixée à l'avance, de ne tester qu'un seul sens ; les tests unilatéraux sont plus puissants mais ne détectent les écarts que dans la direction choisie.