Cohen's d क्या है?
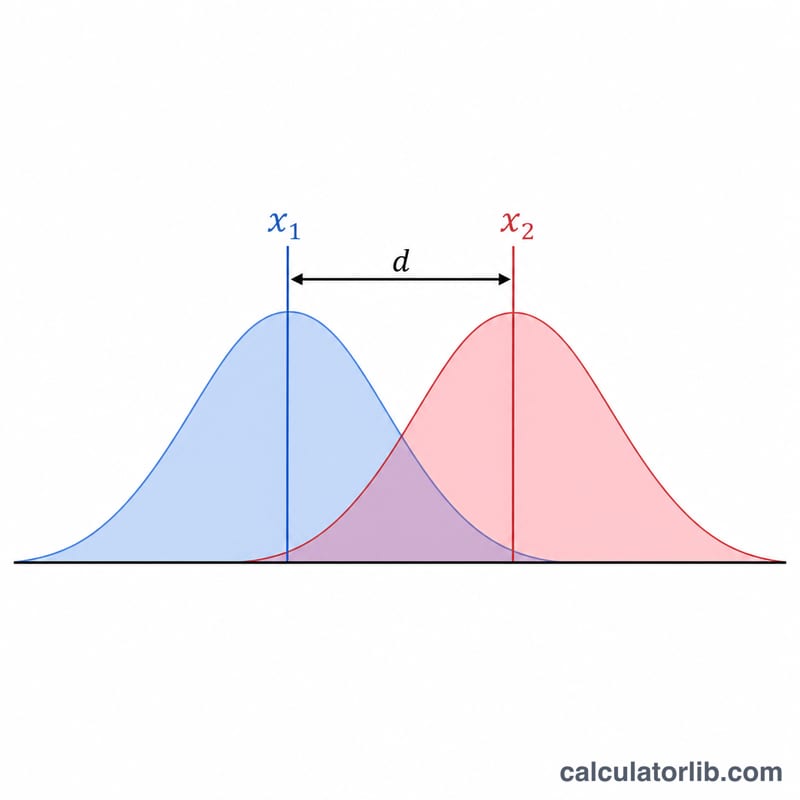
Cohen's d इफेक्ट साइज़ का एक मानकीकृत माप है, जो दो समूहों के माध्य (mean) के बीच के अंतर को पूल्ड मानक विचलन (pooled standard deviation) की इकाइयों में दर्शाता है। p-value केवल यह बताता है कि कोई अंतर सांख्यिकीय रूप से सार्थक है या नहीं, जबकि Cohen's d यह बताता है कि वह अंतर असल में कितना बड़ा है। यही वजह है कि अलग-अलग अध्ययनों के नतीजों की तुलना करने या पावर एनालिसिस के लिए सैंपल साइज़ तय करने में यह बेहद उपयोगी होता है।
इस कैलकुलेटर का उपयोग कैसे करें
अपने दोनों समूहों में से हर एक के लिए माध्य, मानक विचलन और सैंपल साइज़ भरें। कैलकुलेटर पहले पूल्ड मानक विचलन निकालता है, फिर माध्य के अंतर को उससे विभाजित करके Cohen's d देता है। साथ ही यह Cohen के परंपरागत मानकों के आधार पर प्रभाव की मात्रा को वर्गीकृत भी करता है।
फॉर्मूला समझें
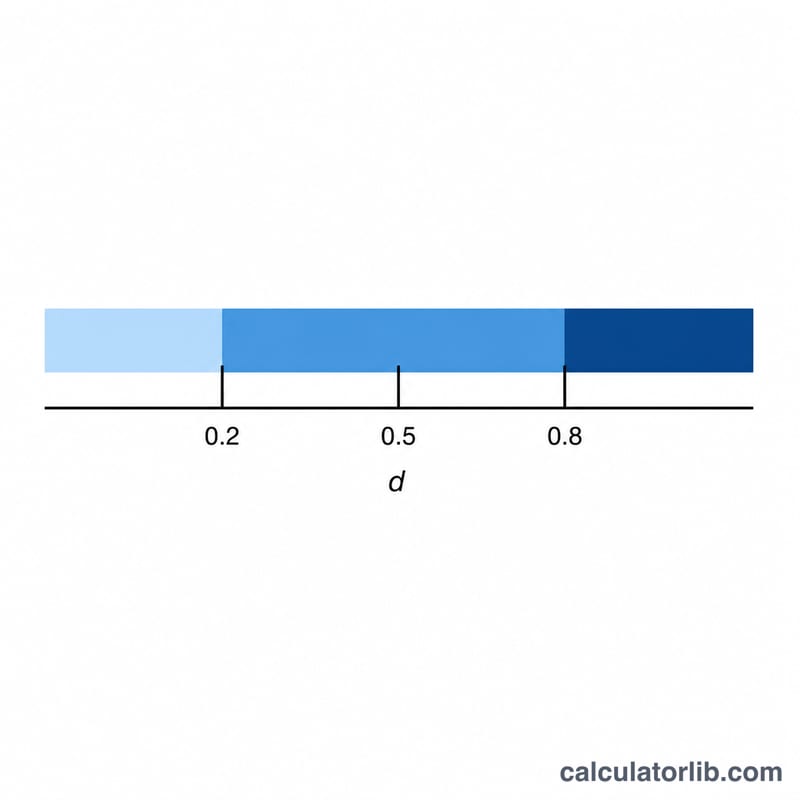
पूल्ड मानक विचलन हर समूह के वेरिएंस को उसकी डिग्रीज़ ऑफ़ फ़्रीडम के अनुसार भार (weight) देता है: $$s_{\text{pooled}} = \sqrt{\frac{(n_1-1)s_1^{2} + (n_2-1)s_2^{2}}{n_1+n_2-2}}$$ इसके बाद Cohen's d होता है \((\bar{x}_1 - \bar{x}_2) / s_{\text{pooled}}\)। परंपरा के अनुसार, \(|d| \approx 0.2\) छोटा प्रभाव, \(0.5\) मध्यम प्रभाव, और \(0.8\) या उससे अधिक बड़ा प्रभाव माना जाता है।
हल किया हुआ उदाहरण
मान लीजिए समूह 1 का माध्य 25, SD 12, n 40 है, और समूह 2 का माध्य 18, SD 9, n 30 है। तब पूल्ड वेरिएंस होगा $$\frac{(39)(144) + (29)(81)}{68} = \frac{5616 + 2349}{68} = 117.1324,$$ इसलिए \(s_{\text{pooled}} \approx 10.8228\)। Cohen's d \(= (25 - 18) / 10.8228 \approx 0.647\), यानी एक मध्यम प्रभाव।
अक्सर पूछे जाने वाले सवाल
क्या d का चिह्न (+/−) मायने रखता है? चिह्न सिर्फ़ यह दिखाता है कि किस समूह का माध्य अधिक है; इफेक्ट साइज़ के लिए असली महत्व उसकी मात्रा (magnitude) का होता है, इसलिए इसे अक्सर निरपेक्ष मान (absolute value) के रूप में बताया जाता है।
किसी एक समूह के SD की बजाय पूल्ड SD क्यों इस्तेमाल करें? पूलिंग दोनों सैंपल की जानकारी को मिला देती है, जिससे साझा फैलाव (common spread) का एक अधिक स्थिर अनुमान मिलता है। यह तब उपयुक्त होता है जब दोनों समूहों के वेरिएंस लगभग बराबर हों।
अगर मेरे समूहों के साइज़ अलग-अलग हों तो? कोई दिक्कत नहीं — डिग्रीज़ ऑफ़ फ़्रीडम पर आधारित भार असमान सैंपल साइज़ को अपने आप संभाल लेता है।