코헨의 d란?
코헨의 d(Cohen's d)는 두 집단 평균의 차이를 합동 표준편차 단위로 나타낸 표준화된 효과크기 지표입니다. p값이 단순히 차이가 통계적으로 유의한지만 알려주는 것과 달리, 코헨의 d는 그 차이가 실제로 얼마나 큰지를 보여 줍니다. 그래서 여러 연구 결과를 서로 비교하거나, 검정력 분석(power analysis)을 위해 표본 크기를 설계할 때 특히 유용합니다.
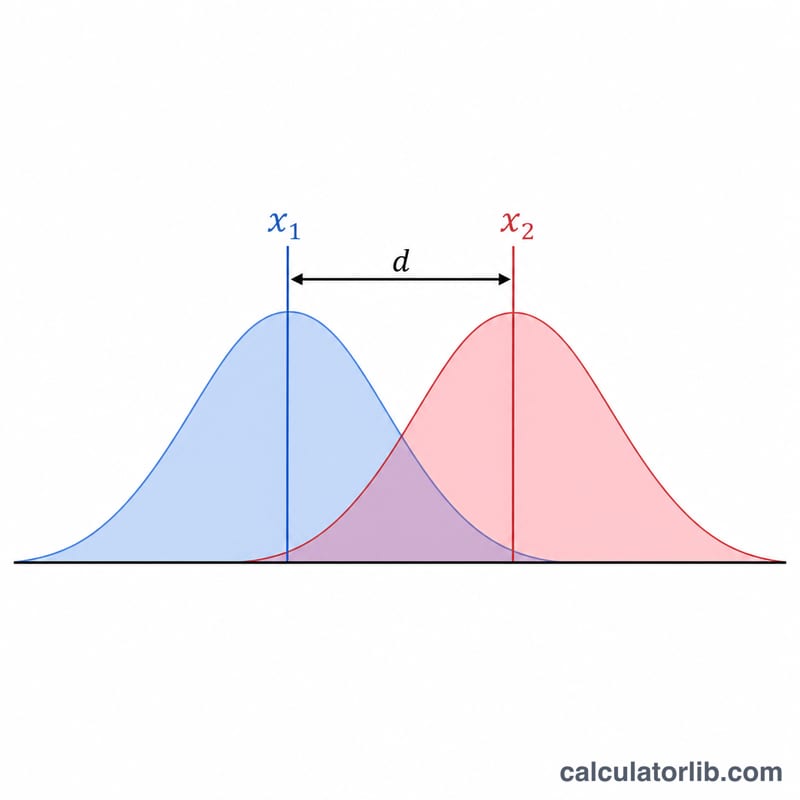
계산기 사용 방법
두 집단 각각의 평균, 표준편차, 표본 크기를 입력하세요. 계산기는 먼저 합동 표준편차를 구한 다음, 평균의 차이를 이 값으로 나누어 코헨의 d를 산출합니다. 또한 코헨이 제시한 관례적 기준에 따라 효과의 크기를 자동으로 분류해 줍니다.
공식 설명
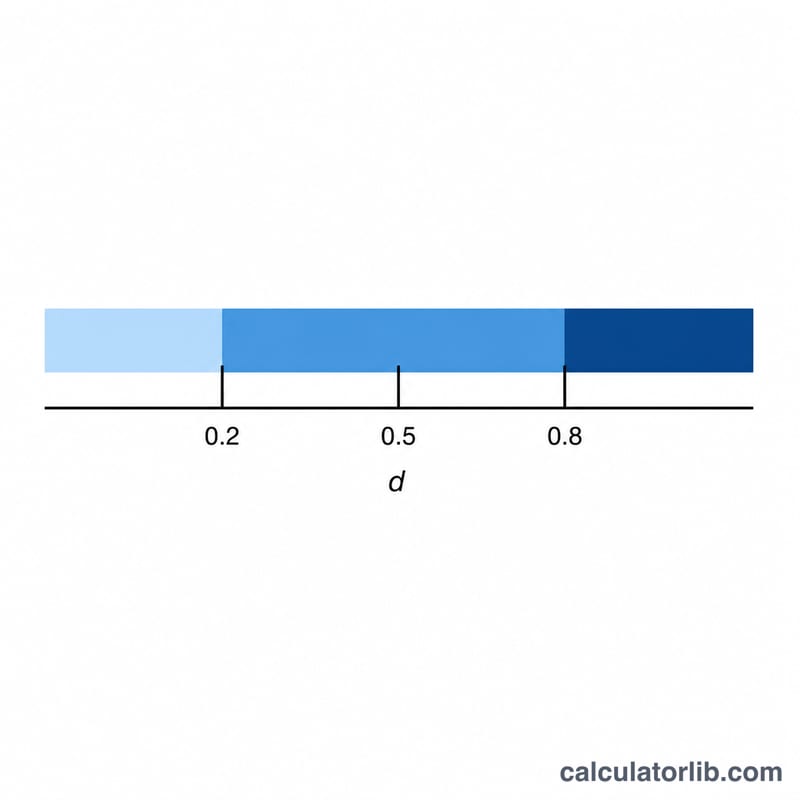
합동 표준편차는 각 집단의 분산을 자유도로 가중하여 계산합니다: $$s_p = \sqrt{\frac{(n_1-1)s_1^{2} + (n_2-1)s_2^{2}}{n_1+n_2-2}}$$ 이렇게 구한 값으로 코헨의 d는 \((\bar{x}_1 - \bar{x}_2) / s_p\)가 됩니다. 관례적으로 \(|d| \approx 0.2\)이면 작은 효과, \(0.5\)이면 중간 효과, \(0.8\) 이상이면 큰 효과로 봅니다.
계산 예시
집단 1의 평균이 25, 표준편차 12, 표본 크기 40이고, 집단 2의 평균이 18, 표준편차 9, 표본 크기 30이라고 가정해 봅시다. 합동 분산은 $$\frac{(39)(144) + (29)(81)}{68} = \frac{5616 + 2349}{68} = 117.1324$$ 가 되고, 따라서 \(s_p \approx 10.8228\)입니다. 코헨의 d $$= \frac{25 - 18}{10.8228} \approx 0.647$$ 로, 중간 정도의 효과에 해당합니다.
자주 묻는 질문
d의 부호(±)에 의미가 있나요? 부호는 단지 어느 집단의 평균이 더 큰지를 나타낼 뿐입니다. 효과크기에서 중요한 것은 크기(절댓값)이므로, 보통 절댓값으로 보고합니다.
한 집단의 표준편차 대신 합동 표준편차를 쓰는 이유는? 합동 표준편차는 두 표본의 정보를 함께 묶어 공통 산포에 대한 더 안정적인 추정값을 제공합니다. 두 집단의 분산이 대체로 비슷할 때 적절한 방법입니다.
두 집단의 크기가 다르면 어떻게 되나요? 문제없습니다. 자유도 가중 방식이 서로 다른 표본 크기를 자동으로 처리해 줍니다.