코헨의 d란?
코헨의 d(Cohen's d)는 두 집단의 평균 차이를 합동 표준편차 단위로 표준화해서 나타내는 효과크기(effect size) 지표입니다. p값이 차이가 통계적으로 유의한지를 알려준다면, 코헨의 d는 그 차이가 실제로 얼마나 큰지를 보여줍니다. 그래서 연구, 심리학, 교육학, 의학 분야에서 결과의 실질적 중요성을 판단할 때 빼놓을 수 없는 값입니다.
계산기 사용법
두 집단 각각의 평균, 표준편차, 표본 크기를 입력하세요. 계산기가 합동 표준편차를 구한 뒤, 두 평균의 차이를 그 값으로 나누어 코헨의 d를 산출하고, 효과 크기에 대한 일반적인 해석까지 함께 제시합니다.
공식 풀이
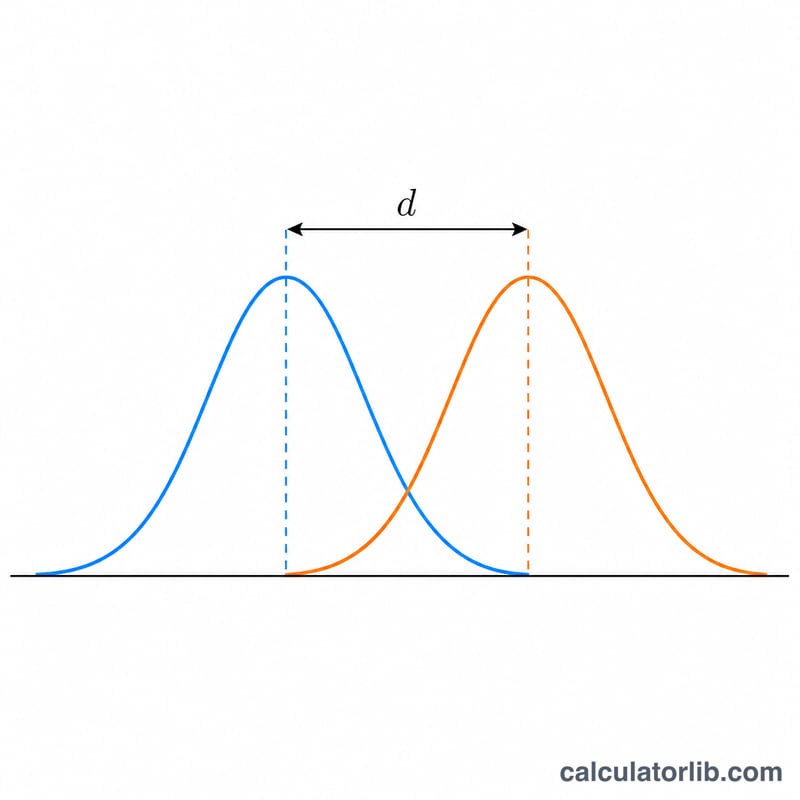
분자는 단순히 M1 − M2, 즉 두 집단 평균의 원래 차이입니다. 분모는 합동 표준편차로, 두 집단의 분산을 각각의 자유도(n − 1)로 가중평균하여 결합한 값입니다. 이 합동 산포로 나누면 차이가 표준화되어, 서로 다른 연구나 측정 척도 사이에서도 비교가 가능해집니다.
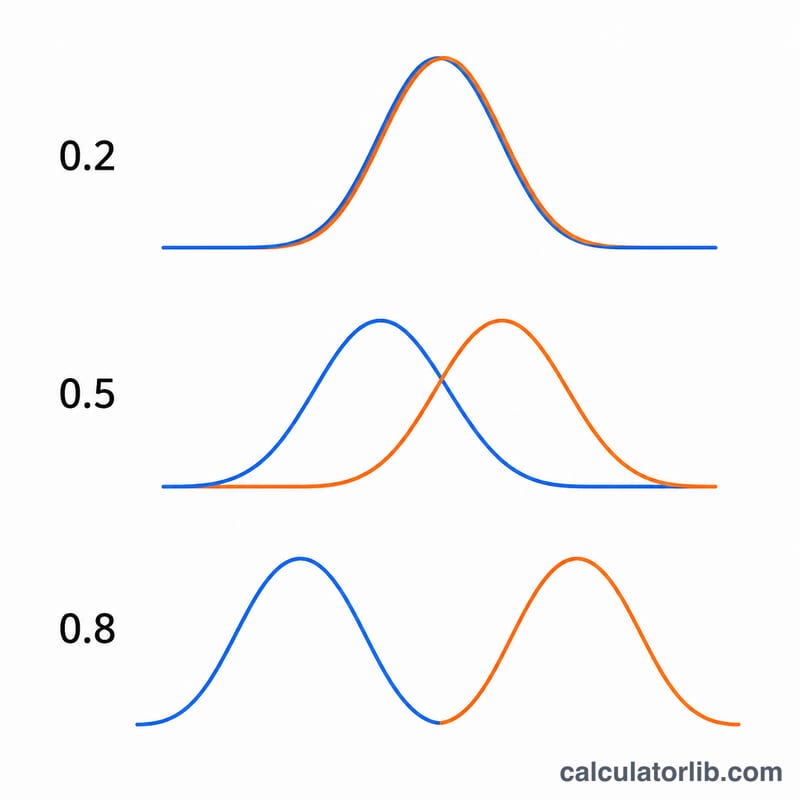
$$\begin{gathered} d = \frac{\text{M1} - \text{M2}}{s_p} \\[1.5em] \text{where}\quad s_p = \sqrt{\frac{(\text{n1}-1)\,\text{s1}^{2} + (\text{n2}-1)\,\text{s2}^{2}}{\text{n1} + \text{n2} - 2}} \end{gathered}$$코헨이 제시한 관례적 기준은 다음과 같습니다. \(d \approx 0.2\)는 작은(small) 효과, \(d \approx 0.5\)는 중간(medium) 효과, \(d \approx 0.8\) 이상은 큰(large) 효과로 봅니다.
예제로 계산해 보기
1집단이 \(\text{M1} = 100\), \(\text{s1} = 15\), \(\text{n1} = 30\)이고, 2집단이 \(\text{M2} = 90\), \(\text{s2} = 12\), \(\text{n2} = 30\)이라고 가정해 봅시다. 합동 분산은 $$\frac{(29 \cdot 225) + (29 \cdot 144)}{58} = \frac{6525 + 4176}{58} = 184.5$$이므로, 합동 표준편차는 약 \(13.5830\)이 됩니다. 따라서 $$d = \frac{100 - 90}{13.5830} \approx 0.7363$$으로, 중간에서 큰 정도의 효과에 해당합니다.
자주 묻는 질문
d의 부호(±)가 중요한가요? 부호는 어느 집단의 평균이 더 높은지를 나타낼 뿐입니다. 효과의 크기를 논할 때는 대개 절댓값을 사용해서 보고합니다.
합동 표준편차는 언제 사용하나요? 합동 표준편차는 두 집단의 분산이 대체로 비슷하다는 전제에서 사용합니다. 분산 차이가 크다면 글래스의 델타(Glass's delta)나 헤지스의 g(Hedges' g)를 고려하는 것이 좋습니다.
헤지스의 g는 무엇인가요? 헤지스의 g는 코헨의 d에 편향 보정 계수를 곱해 작은 표본에서의 편향을 바로잡은 값입니다. 표본이 충분히 크면 두 값은 거의 같아집니다.