सैंपल माध्य की सैंपलिंग वितरण क्या है?
जब आप किसी जनसंख्या (population) से बार-बार n आकार के यादृच्छिक सैंपल निकालते हैं और हर सैंपल का माध्य (mean) निकालते हैं, तो ये सभी माध्य मिलकर अपनी एक अलग वितरण बनाते हैं — इसी को सैंपल माध्य की सैंपलिंग वितरण कहते हैं। यह कैलकुलेटर तीन इनपुट से इस वितरण का केंद्र (माध्य) और फैलाव (मानक त्रुटि) निकालता है: जनसंख्या माध्य μ, जनसंख्या मानक विचलन σ, और सैंपल साइज़ n।
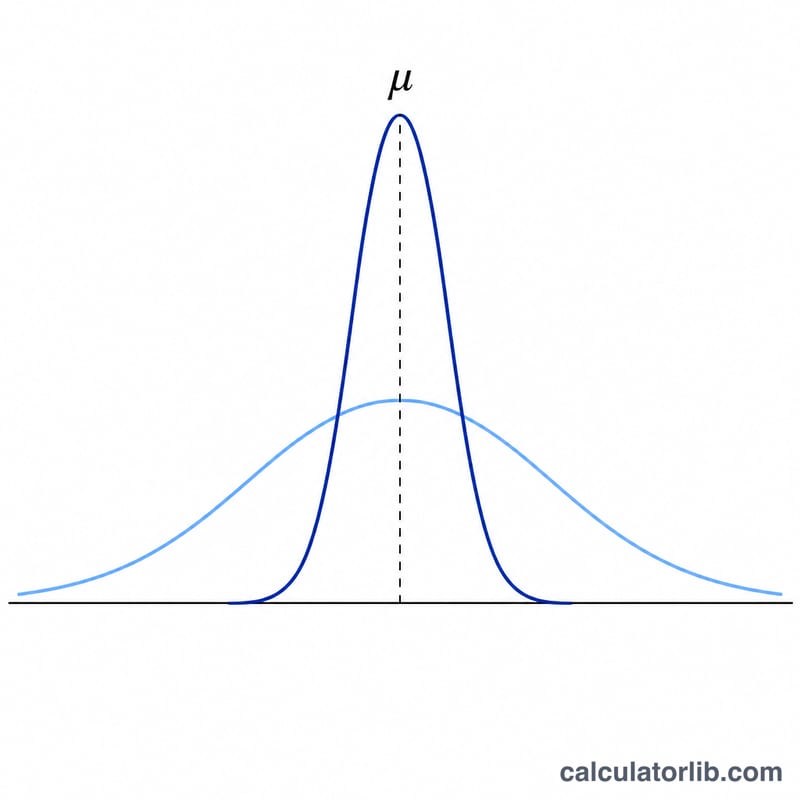
इस कैलकुलेटर का उपयोग कैसे करें
जनसंख्या माध्य (μ), जनसंख्या मानक विचलन (σ) और अपना सैंपल साइज़ (n) दर्ज करें। यह टूल सैंपलिंग वितरण का माध्य (μx̄), मानक त्रुटि (σx̄) और सैंपल माध्य का प्रसरण (σx̄²) बता देता है। मानक त्रुटि यह दर्शाती है कि सैंपल के माध्य आमतौर पर असली जनसंख्या माध्य से कितना अलग होते हैं।
फ़ॉर्मूला को समझें
सैंपलिंग वितरण का माध्य हमेशा जनसंख्या माध्य के बराबर होता है: \(\mu_{\bar{x}} = \mu\)। सैंपल जितने बड़े होते हैं, फैलाव उतना ही कम होता जाता है:
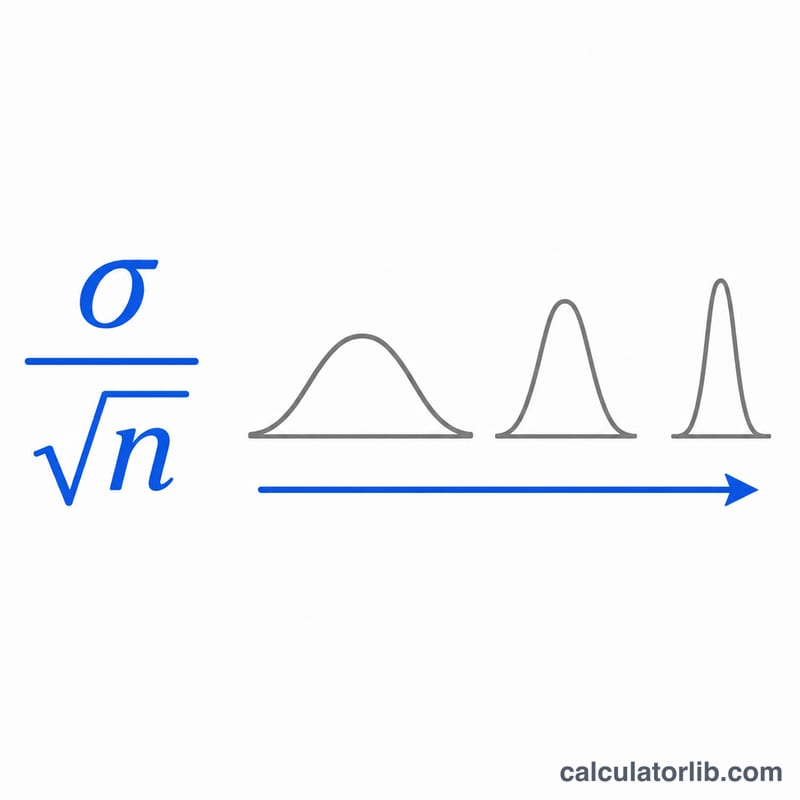
$$\sigma_{\bar{x}} = \frac{\sigma}{\sqrt{n}}$$चूँकि हम \(n\) के वर्गमूल से भाग देते हैं, इसलिए सैंपल साइज़ दोगुना करने से मानक त्रुटि आधी नहीं होती — मानक त्रुटि को आधा करने के लिए आपको \(n\) को चार गुना करना पड़ेगा। केंद्रीय सीमा प्रमेय (Central Limit Theorem) के अनुसार, बड़े \(n\) के लिए यह वितरण लगभग सामान्य (normal) होती है, चाहे जनसंख्या का आकार कैसा भी हो।
हल किया गया उदाहरण
मान लीजिए \(\mu = 100\), \(\sigma = 15\), और \(n = 25\)। तब \(\mu_{\bar{x}} = 100\), और
$$\sigma_{\bar{x}} = \frac{15}{\sqrt{25}} = \frac{15}{5} = 3$$प्रसरण होगा \(\sigma_{\bar{x}}^{2} = 3^{2} = 9\)। यानी 25 अवलोकनों वाले सैंपल के माध्य 100 के आसपास इकट्ठे रहते हैं, जिनकी मानक त्रुटि 3 है।
अक्सर पूछे जाने वाले सवाल
सैंपल बड़े होने पर मानक त्रुटि कम क्यों हो जाती है? बड़े सैंपल में यादृच्छिक उतार-चढ़ाव आपस में संतुलित हो जाते हैं, इसलिए उनके माध्य असली माध्य के और भी करीब, सघन रूप से जमा रहते हैं।
क्या जनसंख्या का सामान्य (normal) होना ज़रूरी है? यहाँ दिए गए फ़ॉर्मूलों के लिए नहीं। माध्य और मानक त्रुटि किसी भी जनसंख्या के लिए सटीक रहते हैं। सैंपलिंग वितरण का सामान्य होना केंद्रीय सीमा प्रमेय के ज़रिए बड़े \(n\) पर लगभग लागू होता है।
अगर मेरे पास सिर्फ़ सैंपल मानक विचलन हो तो? अगर \(\sigma\) पता न हो, तो उसके अनुमान के रूप में सैंपल मानक विचलन \(s\) का उपयोग करें; तब मानक त्रुटि \(s/\sqrt{n}\) हो जाती है, जिसे अक्सर t-वितरण के साथ इस्तेमाल किया जाता है।