F-वितरण कैलकुलेटर क्या है?
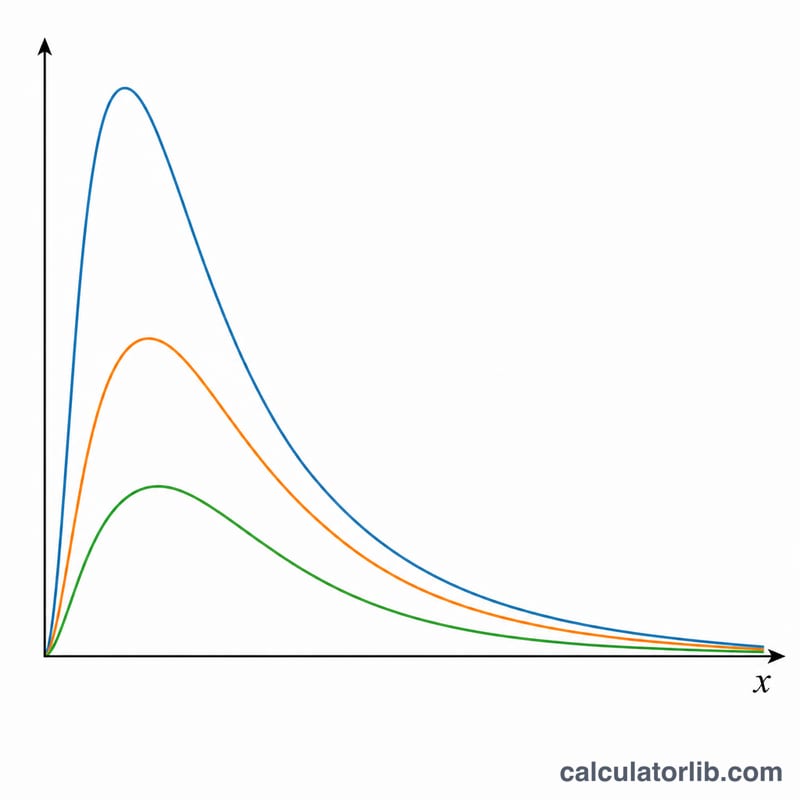
यह टूल किसी दिए गए प्रतिशत बिंदु x और दो स्वतंत्रता कोटि (degrees of freedom) मानों — अंश की v1 और हर की v2 — के लिए F-वितरण (फिशर-स्नेडेकर वितरण) का मान निकालता है। यह प्रायिकता घनत्व f(x), निचली संचयी प्रायिकता P(X ≤ x), और ऊपरी (पुच्छ) प्रायिकता P(X > x) लौटाता है। F-वितरण सांख्यिकी में सर्वव्यापी है और हर जगह एक समान रूप से लागू होता है — इसमें किसी देश-विशेष की धारणा शामिल नहीं है।
इसका उपयोग कैसे करें
प्रतिशत बिंदु x दर्ज करें (यह 0 या उससे बड़ा होना चाहिए), अंश की स्वतंत्रता कोटि v1 (0 से बड़ी) और हर की स्वतंत्रता कोटि v2 (0 से बड़ी) डालें। दोनों df मान पूर्णांक न होकर दशमलव भी हो सकते हैं। कैलकुलेटर घनत्व और दोनों संचयी प्रायिकताएँ लौटाता है, जो हमेशा निचली + ऊपरी = 1 के नियम को संतुष्ट करती हैं।
सूत्र की व्याख्या
घनत्व इस प्रकार है:
$$f(x) = \frac{\sqrt{\dfrac{(v_1\,x)^{v_1}\,v_2^{\,v_2}}{(v_1\,x + v_2)^{v_1+v_2}}}}{x \cdot B\!\left(\dfrac{v_1}{2},\dfrac{v_2}{2}\right)}$$जहाँ \(B\) बीटा फलन है और \(d_1 = v_1\), \(d_2 = v_2\) है। संचयी वितरण नियमितीकृत अपूर्ण बीटा फलन (regularized incomplete beta function) का प्रयोग करता है:
$$P(X \le x) = I_{z}\!\left(\dfrac{v_1}{2},\,\dfrac{v_2}{2}\right),\qquad z = \dfrac{v_1\,x}{v_1\,x + v_2}$$हम log-Gamma की गणना लैन्ज़ोस सन्निकटन (Lanczos approximation) से और अपूर्ण बीटा की गणना सतत भिन्न (continued fraction) यानी लेंट्ज़ विधि (Lentz's method) से करते हैं।
हल किया हुआ उदाहरण
\(x = 1\), \(v_1 = 2\), \(v_2 = 1\) के लिए: \(B(1, 0.5) = 2\), अतः $$f(1) = \frac{2^1 \cdot 1^0 \cdot 3^{-1.5}}{2} = 3^{-1.5} \approx 0.19245$$ CDF के लिए, \(z = 2/3\), और \(I_{2/3}(1, 0.5) = 1 - (1/3)^{0.5} \approx 0.42265\), इसलिए \(P(X > 1) \approx 0.57735\)।
अक्सर पूछे जाने वाले प्रश्न
क्या स्वतंत्रता कोटि दशमलव में हो सकती है? हाँ। F-वितरण किसी भी धनात्मक वास्तविक df के लिए भली-भाँति परिभाषित है।
x = 0 पर क्या होता है? निचली प्रायिकता 0 होती है और ऊपरी 1। घनत्व +अनंत होता है यदि \(v_1 < 2\), यदि \(v_1 = 2\) हो तो 1 के बराबर, और यदि \(v_1 > 2\) हो तो 0।
ऊपरी संचयी प्रायिकता किस काम आती है? यह F-परीक्षण का p-मान है: शून्य परिकल्पना (null hypothesis) के अंतर्गत कम-से-कम x जितना बड़ा F-सांख्यिकीय मान मिलने की संभावना।