द्विपद बंटन क्या है?
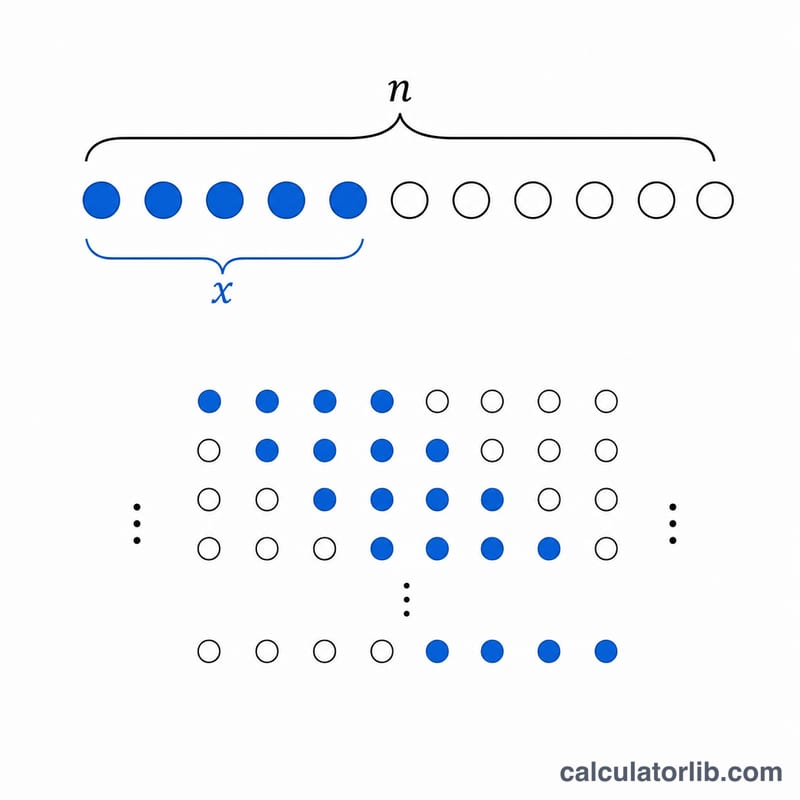
द्विपद बंटन (Binomial Distribution) यह बताता है कि निश्चित संख्या में स्वतंत्र परीक्षणों \(n\) के दौरान कितनी सफलताएँ \(x\) मिलने की संभावना कितनी है, जहाँ हर परीक्षण में सफलता की प्रायिकता समान रूप से \(p\) रहती है (यानी बर्नूली परीक्षण)। यह उन सवालों का जवाब देता है जैसे "20 बार सिक्का उछालने पर ठीक 5 बार चित आने की संभावना कितनी है?" यह विशुद्ध रूप से गणित है, जो हर जगह एक जैसा लागू होता है — इसमें न कोई इकाई होती है और न ही किसी देश के नियमों का असर।
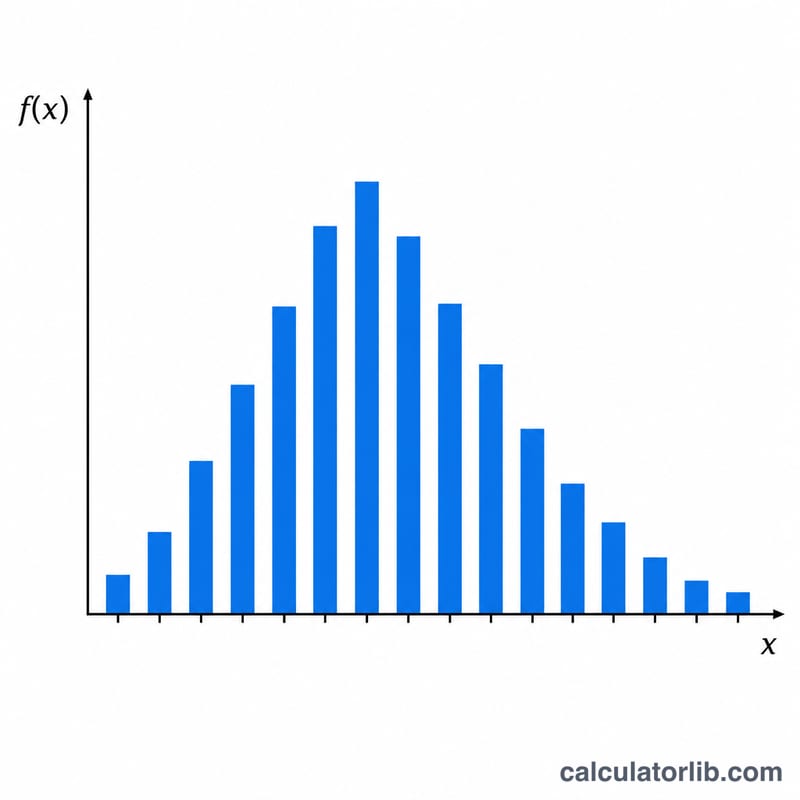
इस कैलकुलेटर का उपयोग कैसे करें
सबसे पहले चुनें कि आप कौन-सा फलन निकालना चाहते हैं: प्रायिकता द्रव्यमान \(f(x)\) (ठीक \(x\) सफलताओं की संभावना), निम्न संचयी \(P(X \le x)\), या उच्च संचयी \(Q(X \ge x)\)। इसके बाद परीक्षणों की संख्या \(n\) दर्ज करें, प्रति परीक्षण सफलता की प्रायिकता \(p\) (0 और 1 के बीच) भरें, फिर पहली सफलता-संख्या (आरंभिक \(x\)), प्रत्येक पंक्ति के बीच का अंतराल (step), और कितनी पंक्तियाँ बनानी हैं — यह सब तय करें। उपकरण चुने गए फलन की तालिका बनाता है और उसे एक असतत हिस्टोग्राम के रूप में ग्राफ़ में दिखाता है, जिसमें सलाखें (bars) एक-दूसरे से सटी रहती हैं।
सूत्र की व्याख्या
प्रायिकता द्रव्यमान फलन है
$$f(x,n,p) = \binom{n}{x}\, p^{\,x}\,(1-p)^{\,n-x}$$जहाँ \(\binom{n}{x} = \dfrac{n!}{x!\,(n-x)!}\) द्विपद गुणांक है। निम्न संचयी \(P(x)\) में \(f\) का योग \(t = 0..x\) तक किया जाता है, और उच्च संचयी \(Q(x)\) में \(f\) का योग \(t = x..n\) तक होता है। बड़े \(n\) के लिए फैक्टोरियल के अतिप्रवाह (overflow) से बचने के लिए यह कैलकुलेटर गुणांक की गणना लॉग-गामा फलन से करता है:
$$\ln f = \ln\Gamma(n+1) - \ln\Gamma(x+1) - \ln\Gamma(n-x+1) + x\cdot\ln p + (n-x)\cdot\ln(1-p)$$इस बंटन का माध्य \(np\) होता है और प्रसरण \(np(1-p)\)।
हल किया हुआ उदाहरण
मान लें \(n = 20\), \(p = 0.25\) और हम PMF को \(x = 0..12\) पर निकालते हैं: \(f(0) \approx 0.003171\), \(f(1) \approx 0.021142\), \(f(2) \approx 0.066948\), \(f(3) \approx 0.133897\), \(f(4) \approx 0.189691\), और \(f(5) \approx 0.202337\)। सबसे ऊँचा मान \(x = 5\) पर आता है, जो माध्य
$$np = 20 \times 0.25 = 5$$के बराबर है — ठीक वैसा ही जैसा अपेक्षित था।
परिभाषाएँ और शब्दकोश
- परीक्षण: एक यादृच्छिक प्रयोग की एकल पुनरावृत्ति जिसमें परिणामों का एक निश्चित, परिभाषित समुच्चय है।
- बर्नौली परीक्षण: एक परीक्षण जिसके ठीक दो परस्पर अनन्य परिणाम हैं, जिन्हें परंपरागत रूप से "सफलता" और "विफलता" कहा जाता है।
- सफलता की संभावना \(p\): वह संभावना कि एक एकल परीक्षण से सफलता मिले, जहाँ \(0 \le p \le 1\)। यह सभी परीक्षणों में स्थिर मानी जाती है।
- परीक्षणों की संख्या \(n\): प्रयोग में स्वतंत्र बर्नौली परीक्षणों की निर्धारित गिनती, एक अऋणात्मक पूर्णांक।
- सफलताएँ \(x\): \(n\) परीक्षणों में देखी गई सफलताओं की संख्या; \(x\) एक पूर्णांक है जहाँ \(0 \le x \le n\)।
- PMF \(f(x)\): प्रायिकता द्रव्यमान फलन, जो ठीक \(x\) सफलताओं की संभावना देता है: \(f(x)=\binom{n}{x}p^{x}(1-p)^{n-x}\)।
- निम्न संचयी \(P(X\le x)\): संचयी वितरण फलन, अधिकतम \(x\) सफलताओं की संभावना: \(P(X\le x)=\sum_{k=0}^{x} f(k)\)।
- उच्च संचयी \(Q(X\ge x)\): कम से कम \(x\) सफलताओं की संभावना: \(Q(X\ge x)=\sum_{k=x}^{n} f(k)=1-P(X\le x-1)\)।
- द्विपद गुणांक \(\binom{n}{x}\): \(n\) परीक्षणों से \(x\) सफलताओं को चुनने के विशिष्ट तरीकों की संख्या, \(\binom{n}{x}=\dfrac{n!}{x!\,(n-x)!}\)।
- माध्य \(np\): सफलताओं की प्रत्याशित संख्या, \(\mu = np\)।
- प्रसरण \(np(1-p)\): सफलताओं की गिनती का प्रसरण, \(\sigma^{2}=np(1-p)\); मानक विचलन है \(\sigma=\sqrt{np(1-p)}\)।
अपने परिणाम की व्याख्या
ये तीनों राशियाँ एक ही प्रयोग के बारे में तीन अलग-अलग प्रश्नों का उत्तर देती हैं:
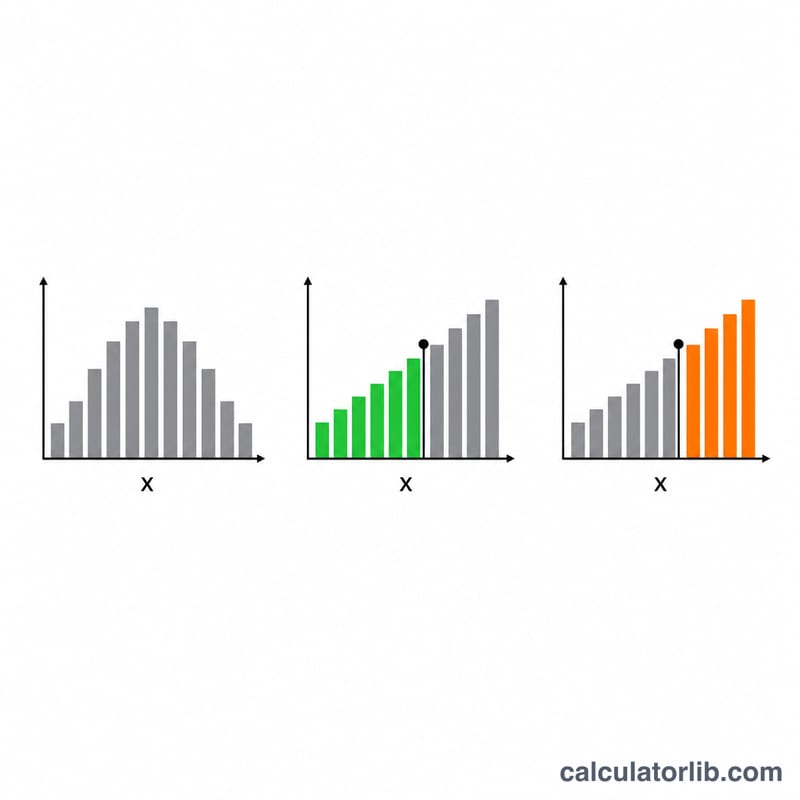
- \(f(x)\) — ठीक \(x\): ठीक \(x\) सफलताएँ प्राप्त करने और कोई अन्य संख्या न प्राप्त करने की संभावना। इसका उपयोग "ठीक k" प्रश्नों के लिए करें।
- \(P(X\le x)\) — अधिकतम \(x\): वह संभावना कि सफलताओं की संख्या \(x\) से अधिक न हो। इसका उपयोग "अधिकतम k," "k से अधिक नहीं," या "k+1 से कम" प्रश्नों के लिए करें।
- \(Q(X\ge x)\) — कम से कम \(x\): \(x\) या अधिक सफलताओं की संभावना। इसका उपयोग "कम से कम k," "k या अधिक," या "k−1 से अधिक" प्रश्नों के लिए करें।
एक वास्तविक प्रश्न को एक फलन में मानचित्रित करना। शब्दावली का सावधानीपूर्वक अनुवाद करें, सीमा पर ध्यान दें:
- "कम से कम \(k\)" \(\Rightarrow Q(X\ge k)\)।
- "k से अधिक" \(\Rightarrow Q(X\ge k+1) = 1 - P(X\le k)\)।
- "अधिकतम \(k\)" \(\Rightarrow P(X\le k)\)।
- "k से कम" \(\Rightarrow P(X\le k-1)\)।
- "\(a\) और \(b\) के बीच (समावेशी)" \(\Rightarrow P(X\le b) - P(X\le a-1)\)।
\(P\)/\(Q\) अतिव्यापन। क्योंकि \(P(X\le x)\) और \(Q(X\ge x)\) दोनों में शब्द \(f(x)\) शामिल है, वे एक ही \(x\) पर पूरक नहीं हैं। वास्तव में \(P(X\le x) + Q(X\ge x) = 1 + f(x)\), इसलिए दोनों संचयी पूँछें ठीक एक बिंदु द्रव्यमान द्वारा अतिव्यापी हैं। \(Q(X\ge x)\) का सच्चा पूरक \(P(X\le x-1)\) है, \(P(X\le x)\) नहीं।
सामान्य सन्निकटन। जब \(np\) और \(n(1-p)\) दोनों उचित रूप से बड़े हों (एक सामान्य अंगुष्ठ का नियम यह है कि प्रत्येक \(\ge 5\) हो, और आदर्श रूप से \(\ge 10\) हो), तो द्विपद को माध्य \(\mu = np\) और मानक विचलन \(\sigma = \sqrt{np(1-p)}\) वाले सामान्य वितरण द्वारा अच्छी तरह से सन्निकटित किया जाता है। एक सतत सामान्य पैमाने पर असतत गिनती को परिवर्तित करते समय सातत्य सुधार (उदाहरण के लिए, \(x+0.5\) या \(x-0.5\) का उपयोग करें) लागू करें। बड़े \(n\) के लिए छोटे \(p\) के साथ (ताकि \(np\) मध्यम रहे), पॉसों वितरण जहाँ \(\lambda = np\) अधिक सटीक सन्निकटन है।
अक्सर पूछे जाने वाले सवाल
\(P(x) + Q(x)\) का योग 1 क्यों नहीं होता? दोनों संचयी मानों में बिंदु \(t = x\) शामिल होता है, इसलिए \(P(x) + Q(x) = 1 + f(x)\)। यह अध्यारोपण (overlap) का तरीका — जहाँ निम्न संचयी में \(x\) शामिल है और उच्च संचयी में भी \(x\) शामिल है — यहाँ जानबूझकर अपनाया गया है।
अगर \(x\) का मान \(0..n\) की सीमा से बाहर हो तो? ऐसे में PMF का मान 0 होता है; निम्न संचयी 0 (जब \(x < 0\)) या 1 (जब \(x \ge n\)) पर सीमित हो जाता है, और उच्च संचयी 1 (जब \(x \le 0\)) या 0 (जब \(x > n\)) पर सीमित हो जाता है।
क्या मैं बड़े \(n\) का उपयोग कर सकता हूँ? हाँ। लॉग-गामा गणना बड़े \(n\) के लिए भी परिणाम को स्थिर रखती है, जबकि सीधे फैक्टोरियल इस्तेमाल करने पर मान अतिप्रवाह (overflow) कर जाते।