이항분포란?
이항분포는 동일한 성공 확률 p를 갖는 독립 시행(베르누이 시행)을 정해진 횟수 n만큼 반복했을 때, 성공이 x번 일어날 확률을 나타내는 분포입니다. 예를 들어 "동전을 20번 던졌을 때 정확히 5번 앞면이 나올 확률은 얼마일까?"와 같은 질문에 답을 줍니다. 이는 순수 수학 개념이므로 단위나 국가에 상관없이 전 세계 어디서나 동일하게 적용됩니다.
계산기 사용법
먼저 어떤 함수를 계산할지 선택하세요. 확률질량 \(f(x)\)(정확히 x번 성공할 확률), 하측 누적 \(P(X \le x)\), 또는 상측 누적 \(Q(X \ge x)\) 중에서 고를 수 있습니다. 이어서 시행 횟수 \(n\), 시행당 성공 확률 \(p\)(0과 1 사이)를 입력하고, 시작 성공 횟수(초기 x), 행 사이의 증가폭(step), 생성할 행의 개수를 지정합니다. 그러면 선택한 함수가 표로 정리되고, 막대가 서로 맞닿은 이산 히스토그램 형태의 그래프로 그려집니다.
공식 풀이
확률질량함수는 다음과 같으며,
$$f(x,n,p) = \binom{n}{x}\, p^{\,x}\,(1-p)^{\,n-x}$$여기서 \(\binom{n}{x} = \dfrac{n!}{x!\,(n-x)!}\) 는 이항계수입니다. 하측 누적 \(P(x)\)는 \(t = 0..x\) 범위에서 \(f\)를 합한 값이고, 상측 누적 \(Q(x)\)는 \(t = x..n\) 범위에서 \(f\)를 합한 값입니다. n이 클 때 팩토리얼이 오버플로되는 것을 막기 위해, 이 계산기는 로그 감마 함수를 이용해 계수를 구합니다. 즉
$$\ln f = \ln\Gamma(n+1) - \ln\Gamma(x+1) - \ln\Gamma(n-x+1) + x\cdot\ln p + (n-x)\cdot\ln(1-p)$$로 계산합니다. 분포의 평균은 \(np\)이고 분산은 \(np(1-p)\)입니다.
계산 예시
\(n = 20\), \(p = 0.25\)일 때 \(x = 0..12\)에서 PMF를 계산하면 다음과 같습니다. \(f(0) \approx 0.003171\), \(f(1) \approx 0.021142\), \(f(2) \approx 0.066948\), \(f(3) \approx 0.133897\), \(f(4) \approx 0.189691\), \(f(5) \approx 0.202337\). 최댓값은 \(x = 5\)에서 나타나며, 이는 평균 $$np = 20 \times 0.25 = 5$$와 정확히 일치합니다.
정의 및 용어
- 시행: 고정되고 정의된 결과 집합을 가진 무작위 실험의 단일 반복.
- 베르누이 시행: 정확히 두 개의 상호 배타적 결과를 가진 시행으로, 관례상 "성공"과 "실패"로 표시됨.
- 성공 확률 \(p\): 단일 시행이 성공으로 끝날 확률로, \(0 \le p \le 1\). 모든 시행에 걸쳐 상수로 가정됨.
- 시행 횟수 \(n\): 실험의 독립적인 베르누이 시행의 고정된 개수로, 음이 아닌 정수.
- 성공 \(x\): \(n\)회 시행 중 관찰된 성공 횟수로, \(x\)는 \(0 \le x \le n\)인 정수.
- 확률질량함수 \(f(x)\): 정확히 \(x\)번 성공할 확률을 나타내는 확률질량함수: \(f(x)=\binom{n}{x}p^{x}(1-p)^{n-x}\).
- 하측 누적분포 \(P(X\le x)\): 누적분포함수로, 최대 \(x\)번 성공할 확률: \(P(X\le x)=\sum_{k=0}^{x} f(k)\).
- 상측 누적분포 \(Q(X\ge x)\): 최소 \(x\)번 성공할 확률: \(Q(X\ge x)=\sum_{k=x}^{n} f(k)=1-P(X\le x-1)\).
- 이항계수 \(\binom{n}{x}\): \(n\)회 시행 중에서 \(x\)번의 성공을 선택하는 서로 다른 방법의 수로, \(\binom{n}{x}=\dfrac{n!}{x!\,(n-x)!}\).
- 평균 \(np\): 기댓값인 예상 성공 횟수로, \(\mu = np\).
- 분산 \(np(1-p)\): 성공 횟수의 분산으로, \(\sigma^{2}=np(1-p)\); 표준편차는 \(\sigma=\sqrt{np(1-p)}\).
결과 해석
세 수량은 같은 실험에 대한 세 가지 다른 질문에 답합니다:
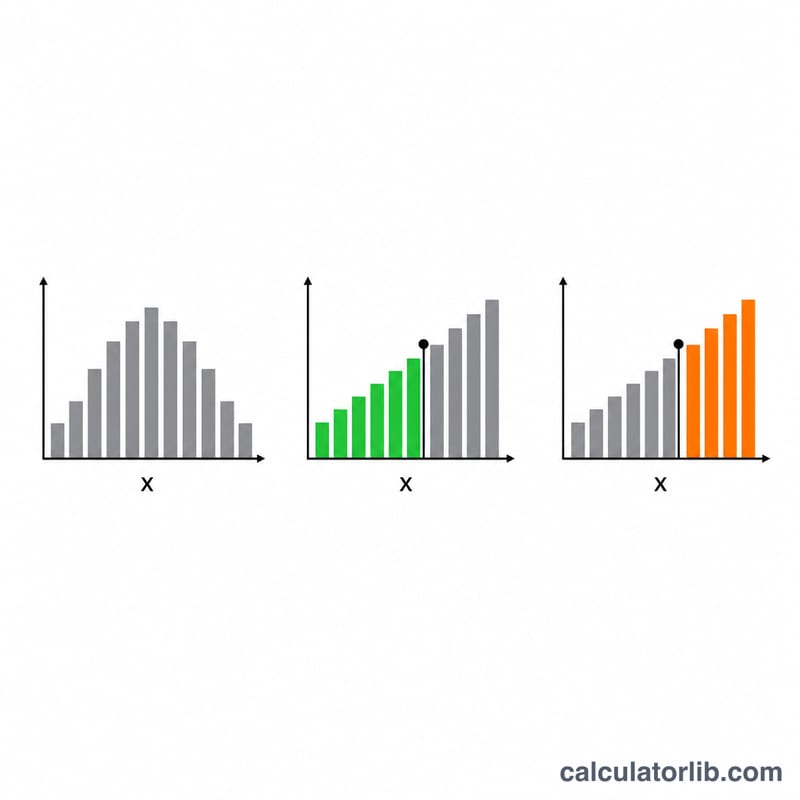
- \(f(x)\) — 정확히 \(x\): 정확히 \(x\)번 성공하고 다른 개수는 아닐 확률. "정확히 k"의 질문에 사용함.
- \(P(X\le x)\) — 최대 \(x\): 성공 횟수가 \(x\)를 초과하지 않을 확률. "최대 k", "k 이하", "k+1 미만"의 질문에 사용함.
- \(Q(X\ge x)\) — 최소 \(x\): \(x\)번 이상의 성공 확률. "최소 k", "k 이상", "k−1 초과"의 질문에 사용함.
실제 질문을 함수에 대응시키기. 표현을 신중하게 번역하고 경계에 주의하세요:
- "최소 \(k\)" \(\Rightarrow Q(X\ge k)\).
- "\(k\) 초과" \(\Rightarrow Q(X\ge k+1) = 1 - P(X\le k)\).
- "최대 \(k\)" \(\Rightarrow P(X\le k)\).
- "\(k\) 미만" \(\Rightarrow P(X\le k-1)\).
- "\(a\)에서 \(b\) 사이 (포함)" \(\Rightarrow P(X\le b) - P(X\le a-1)\).
\(P\)/\(Q\) 겹침. \(P(X\le x)\)와 \(Q(X\ge x)\) 모두 항 \(f(x)\)를 포함하므로, 같은 \(x\)에서 여사건이 아닙니다. 실제로 \(P(X\le x) + Q(X\ge x) = 1 + f(x)\)이므로, 두 누적분포의 꼬리는 정확히 한 점의 확률질량으로 겹칩니다. \(Q(X\ge x)\)의 진정한 여사건은 \(P(X\le x-1)\)이고, \(P(X\le x)\)가 아닙니다.
정규분포 근사. \(np\)와 \(n(1-p)\) 모두가 적당히 크면 (일반적인 경험 규칙은 각각 5 이상이고, 이상적으로는 10 이상), 이항분포는 평균 \(\mu = np\)와 표준편차 \(\sigma = \sqrt{np(1-p)}\)인 정규분포로 잘 근사됩니다. 이산 횟수를 연속 정규분포 척도로 변환할 때 연속성 수정을 적용하세요(예: \(x+0.5\) 또는 \(x-0.5\) 사용). \(np\)가 중간 정도로 유지되는 작은 \(p\)를 가진 큰 \(n\)의 경우, \(\lambda = np\)인 포아송 분포가 더 정확한 근사입니다.
자주 묻는 질문
왜 P(x) + Q(x)가 1이 되지 않나요? 두 누적확률 모두 점 \(t = x\)를 포함하기 때문에 \(P(x) + Q(x) = 1 + f(x)\)가 됩니다. 여기서는 하측과 상측 모두 x를 포함하는 이 중복 규약을 의도적으로 사용합니다.
x가 0..n 범위를 벗어나면 어떻게 되나요? 이 경우 PMF는 0이 됩니다. 하측 누적은 \(x < 0\)이면 0으로, \(x \ge n\)이면 1로 고정되고, 상측 누적은 \(x \le 0\)이면 1로, \(x > n\)이면 0으로 고정됩니다.
큰 n 값도 사용할 수 있나요? 네, 가능합니다. 로그 감마 방식으로 계산하므로 직접 팩토리얼을 쓰면 오버플로가 발생할 만큼 큰 n에서도 결과가 안정적으로 유지됩니다.