द्विपद वितरण कैलकुलेटर क्या है?
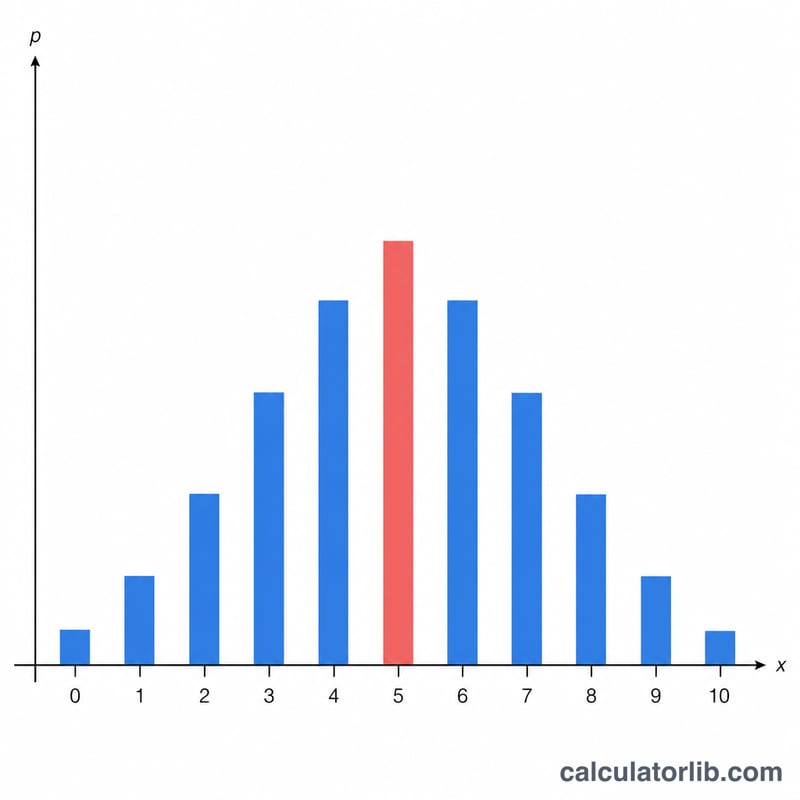
यह टूल एक निश्चित संख्या में स्वतंत्र परीक्षणों के लिए द्विपद वितरण की गणना करता है। आप सफलताओं की संख्या x, परीक्षणों की संख्या n, और एक परीक्षण में सफलता की प्रायिकता p देते हैं, और यह ठीक x सफलताओं की प्रायिकता (प्रायिकता द्रव्यमान), निम्न संचयी प्रायिकता, उच्च संचयी प्रायिकता और माध्य लौटाता है। द्विपद मॉडल तब लागू होता है जब आप एक ही हाँ/नहीं वाला प्रयोग एक निश्चित संख्या में, हर बार समान सफलता संभावना के साथ दोहराते हैं — जैसे सिक्का उछालना, किसी बैच में खराब पुर्जों की संख्या, या अनुमान लगाकर सही किए गए क्विज़ प्रश्न।
इसका उपयोग कैसे करें
तीन शुद्ध संख्याएँ दर्ज करें। सफलताएँ x और परीक्षण n पूर्ण संख्याएँ होनी चाहिए, जहाँ \(0 \le x \le n\) और \(n \ge 1\)। प्रायिकता p का मान 0 और 1 के बीच होना चाहिए। चारों परिणाम एक साथ पाने के लिए "गणना करें" दबाएँ। ध्यान दें कि यह एक विविक्त (discrete) वितरण है, इसलिए मुख्य आँकड़ा एक प्रायिकता द्रव्यमान (एक वास्तविक प्रायिकता) है, प्रायिकता घनत्व नहीं।
सूत्र की व्याख्या
प्रायिकता द्रव्यमान है
$$f(x,n,p) = \binom{n}{x} \, p^{x} \, (1-p)^{n-x}$$जहाँ \(\binom{n}{x} = \dfrac{n!}{x!\,(n-x)!}\) द्विपद गुणांक है जो बताता है कि n परीक्षणों में x सफलताएँ कितने तरीकों से हो सकती हैं। निम्न संचयी प्रायिकता \(P(X \le x)\) में \(t = 0\) से \(x\) तक \(f(t)\) का योग होता है, और उच्च संचयी \(Q(X \ge x)\) में \(t = x\) से \(n\) तक \(f(t)\) का योग होता है। चूँकि बिंदु \(t = x\) दोनों योगों में शामिल है, इसलिए \(P + Q - f(x) = 1\) होता है। माध्य बस \(\mu = n \cdot p\) है। बड़े n के लिए स्थिरता बनाए रखने हेतु गुणांकों की गणना लॉग-फैक्टोरियल से की जाती है।

हल किया गया उदाहरण
\(x = 9\), \(n = 20\), \(p = 0.4\) के लिए: \(\binom{20}{9} = 167960\), \(p^{9} = 0.000262144\), और \(0.6^{11} \approx 0.0036279706\)। तो
$$f = 167960 \times 0.000262144 \times 0.0036279706 \approx 0.15974$$माध्य \(= 20 \times 0.4 = 8\)। योग करने पर \(P(X \le 9) \approx 0.75534\) और \(Q(X \ge 9) \approx 0.40440\) मिलता है, जो \(0.75534 + 0.40440 - 0.15974 \approx 1\) को संतुष्ट करते हैं।
परिभाषाएं और शब्दावली
द्विपद वितरण एक निश्चित संख्या में स्वतंत्र हां/नहीं प्रयोगों में सफलताओं की संख्या को मॉडल करता है। नीचे दिए गए शब्द इस कैलकुलेटर में पूरे समय दिखाई देते हैं।
- परीक्षण: प्रयोग का एक एकल दोहराव जिसके परिणामस्वरूप दो संभावित परिणामों में से एक होता है (उदाहरण के लिए एक सिक्का फ्लिप)।
- सफलता: वह परिणाम जिसे आप गिन रहे हैं, आप इसे जो कुछ भी परिभाषित करते हैं (सिर, एक त्रुटिपूर्ण भाग, एक सही अनुमान)। इसका पूरक एक "विफलता" है।
- n (परीक्षणों की संख्या): किए गए स्वतंत्र परीक्षणों की कुल संख्या। यह एक निश्चित सकारात्मक पूर्णांक होना चाहिए।
- x (सफलताओं की संख्या): सफलताओं की विशिष्ट संख्या जिसकी संभावना आप चाहते हैं, जहां \(0 \le x \le n\)।
- p (सफलता की संभावना): संभावना है कि कोई भी एकल परीक्षण सफल है, 0 और 1 के बीच एक दशमलव।
- q = 1 − p (विफलता की संभावना): संभावना है कि एक एकल परीक्षण विफल है।
- द्विपद गुणांक \(\binom{n}{x}\): अलग-अलग तरीकों की संख्या यह चुनने के लिए कि \(n\) परीक्षणों में से कौन से \(x\) सफलताएं हैं, जिसकी गणना \(\binom{n}{x}=\dfrac{n!}{x!\,(n-x)!}\) के रूप में की जाती है।
- संभावना द्रव्यमान फ़ंक्शन (pmf), \(f(x)\): \(x\) सफलताओं की सटीक संभावना, \(f(x)=\binom{n}{x}p^{x}(1-p)^{n-x}\)।
- निचली संचयी संभावना, \(P(X \le x)\): अधिकतम \(x\) सफलताओं की संभावना, 0 से \(x\) तक के pmf मानों का योग।
- ऊपरी संचयी संभावना, \(P(X \ge x)\): कम से कम \(x\) सफलताओं की संभावना, \(x\) से \(n\) तक के pmf मानों का योग।
- माध्य (अपेक्षित मान), \(\mu = np\): कई दोहरावों में अपेक्षित सफलताओं की औसत संख्या।
- विचरण, \(\sigma^{2}=np(1-p)\): इसके माध्य के चारों ओर वितरण का प्रसार।
- मानक विचलन, \(\sigma=\sqrt{np(1-p)}\): माध्य से सफलता गणना का विशिष्ट विचलन, \(x\) के समान इकाइयों में।
अपने परिणाम की व्याख्या करना
यह कैलकुलेटर तीन संभावनाएं और माध्य प्रदान करता है। वह चुनें जो आपके प्रश्न की व्याख्या से मेल खाता है:
- pmf, \(f(x)=P(X=x)\) — उपयोग करें जब आप \(x\) सफलताओं की सटीक संभावना चाहते हैं, उदाहरण के लिए "10 फ्लिप में बिल्कुल 5 सिर।"
- निचली संचयी, \(P(X \le x)\) — अधिकतम \(x\) ("\(x\) या कम") के लिए उपयोग करें, उदाहरण के लिए "5 या कम सही उत्तर।"
- ऊपरी संचयी, \(P(X \ge x)\) — कम से कम \(x\) ("\(x\) या अधिक") के लिए उपयोग करें, उदाहरण के लिए "कम से कम 1 त्रुटिपूर्ण भाग।"
\(x\) पर संचयी टुकड़े ओवरलैप होते हैं: \(P(X \le x)+P(X \ge x)=1+f(x)\), क्योंकि दोनों श्रेणियां मान \(x\) को ही शामिल करती हैं। \(x\) से सख्ती से कम पाने के लिए, \(P(X \le x-1)\) का उपयोग करें; \(x\) से सख्ती से अधिक के लिए, \(P(X \ge x+1)\) का उपयोग करें।
माध्य \(np\) अपेक्षित सफलताओं की संख्या है — दीर्घकालीन औसत यदि आप पूरे \(n\)-परीक्षण प्रयोग को कई बार दोहराते हैं। यह एक पूर्ण संख्या होने की आवश्यकता नहीं है; 4.5 का अपेक्षित मान बस एक औसत का वर्णन करता है।
सभी संभावनाओं की रिपोर्ट 0 और 1 के बीच दशमलव (प्रतिशत के लिए 100 से गुणा करें) के रूप में की जाती है। 0 के पास एक मान का मतलब है कि घटना दुर्लभ है; 1 के पास, लगभग निश्चित है।
ये परिणाम केवल तभी मान्य हैं जब चार द्विपद धारणाएं सही हों:
- परीक्षणों की निश्चित संख्या \(n\), परिणामों को देखने से पहले तय की गई।
- प्रति परीक्षण दो परिणाम — प्रत्येक परीक्षण एक सफलता या एक विफलता है।
- सफलता की निरंतर संभावना \(p\) प्रत्येक परीक्षण पर।
- स्वतंत्रता — एक परीक्षण का परिणाम किसी अन्य को प्रभावित नहीं करता है।
यदि परीक्षण स्वतंत्र नहीं हैं या \(p\) परीक्षणों के बीच परिवर्तित होता है (उदाहरण के लिए, एक छोटी आबादी से प्रतिस्थापन के बिना नमूनाकरण), तो द्विपद मॉडल केवल एक सन्निकटन है।
अक्सर पूछे जाने वाले प्रश्न
क्या उच्च संचयी में x शामिल होता है? हाँ। यहाँ \(Q(X \ge x)\) में बिंदु \(t = x\) शामिल है, इसलिए यह \(P(X \ge x)\) है, \(P(X > x)\) नहीं।
p=0 या p=1 पर क्या होता है? \(0^{0}=1\) परिपाटी के अनुसार, \(p=0\) देने पर \(f(0)=1\) और बाकी सभी प्रायिकताएँ 0 हो जाती हैं; \(p=1\) देने पर \(f(n)=1\) होता है।
"प्रायिकता द्रव्यमान" क्यों, "घनत्व" क्यों नहीं? घनत्व सतत (continuous) वितरणों पर लागू होता है; विविक्त चर के लिए प्रत्येक परिणाम की एक वास्तविक प्रायिकता होती है, इसलिए "द्रव्यमान" ही सही शब्द है।