이항분포 계산기란?
이 도구는 독립적인 시행을 정해진 횟수만큼 반복할 때의 이항분포를 계산합니다. 성공 횟수 x, 시행 횟수 n, 1회 시행당 성공 확률 p를 입력하면 정확히 x번 성공할 확률(확률질량)과 하측 누적확률, 상측 누적확률, 그리고 평균을 한꺼번에 구해 줍니다. 이항모형은 동일한 '예/아니오' 실험을 일정한 성공 확률로 정해진 횟수만큼 반복하는 모든 상황에 적용됩니다. 예를 들어 동전 던지기, 한 묶음 속 불량품 개수, 찍어서 맞힌 시험 문제 수 등이 여기에 해당합니다.
사용 방법
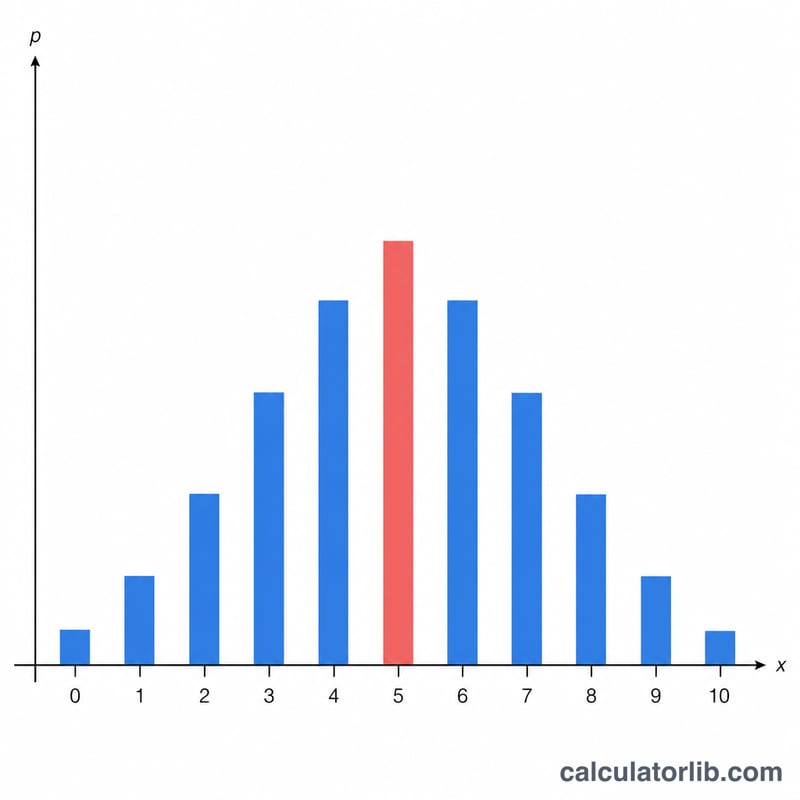
세 개의 숫자만 입력하면 됩니다. 성공 횟수 x와 시행 횟수 n은 \(0 \le x \le n\), \(n \ge 1\)을 만족하는 정수여야 합니다. 확률 p는 0과 1 사이의 값이어야 합니다. 계산 버튼을 누르면 네 가지 결과가 동시에 표시됩니다. 이항분포는 이산분포이므로 대표 결과값은 확률 질량(실제 확률값)이며, 확률 밀도가 아니라는 점에 유의하세요.
공식 풀이
확률질량은 다음과 같습니다.
$$P(X = \text{x}) = \binom{\text{n}}{\text{x}} \, \text{p}^{\,\text{x}} \left(1 - \text{p}\right)^{\text{n} - \text{x}}$$여기서 \(C(n,x) = \dfrac{n!}{x!\,(n-x)!}\)는 이항계수로, n번의 시행 중 x번 성공이 나타나는 경우의 수를 셉니다. 하측 누적확률 \(P(X \le x)\)는 \(t = 0\)부터 x까지 \(f(t)\)를 더한 값이고, 상측 누적확률 \(Q(X \ge x)\)는 \(t = x\)부터 n까지 \(f(t)\)를 더한 값입니다.
$$\begin{gathered} P(X \le \text{x}) = \sum_{t=0}^{\text{x}} \binom{\text{n}}{t} p^{t}(1-p)^{\,\text{n}-t} \\[0.8em] P(X \ge \text{x}) = \sum_{t=\text{x}}^{\text{n}} \binom{\text{n}}{t} p^{t}(1-p)^{\,\text{n}-t} \\[0.8em] \mu = \text{n} \cdot \text{p} \end{gathered}$$\(t = x\) 지점이 두 합에 모두 포함되므로 \(P + Q - f(x) = 1\)이 성립합니다. 평균은 단순히 \(\mu = n \cdot p\)입니다. 큰 n에서도 수치적으로 안정적으로 계산하기 위해 계수는 로그 팩토리얼을 사용해 산출합니다.

계산 예시
\(x = 9\), \(n = 20\), \(p = 0.4\)인 경우: \(C(20,9) = 167960\), \(p^{9} = 0.000262144\), \(0.6^{11} \approx 0.0036279706\)입니다. 따라서
$$f = 167960 \times 0.000262144 \times 0.0036279706 \approx 0.15974$$가 됩니다. 평균은 \(20 \times 0.4 = 8\)입니다. 누적합을 구하면 \(P(X \le 9) \approx 0.75534\), \(Q(X \ge 9) \approx 0.40440\)이며, \(0.75534 + 0.40440 - 0.15974 \approx 1\)을 만족합니다.
정의 및 용어집
이항분포는 고정된 횟수의 독립적인 예/아니오 실험에서 성공의 개수를 모델링합니다. 아래 용어들은 이 계산기 전체에서 나타납니다.
- 시행(Trial): 두 가지 가능한 결과 중 하나를 낳는 실험의 단일 반복(예: 동전 던지기 한 번).
- 성공(Success): 여러분이 정의한 셈하고자 하는 결과(앞면, 불량품, 정답 맞춤). 그 여사건을 "실패"라고 합니다.
- n (시행 횟수): 수행된 독립적 시행의 총 개수. 고정된 양의 정수여야 합니다.
- x (성공의 개수): 확률을 구하고자 하는 성공의 구체적 개수이며, \(0 \le x \le n\)를 만족합니다.
- p (성공 확률): 어떤 단일 시행이 성공일 확률이며, 0과 1 사이의 소수입니다.
- q = 1 − p (실패 확률): 단일 시행이 실패일 확률입니다.
- 이항계수 \(\binom{n}{x}\): \(n\)번의 시행 중 어느 \(x\)번이 성공인지 선택하는 서로 다른 방법의 개수이며, \(\binom{n}{x}=\dfrac{n!}{x!\,(n-x)!}\)로 계산됩니다.
- 확률질량함수(pmf), \(f(x)\): 정확히 \(x\)번 성공할 확률이며, \(f(x)=\binom{n}{x}p^{x}(1-p)^{n-x}\)입니다.
- 하측 누적확률, \(P(X \le x)\): 최대 \(x\)번 성공할 확률이며, 0부터 \(x\)까지의 pmf 값의 합입니다.
- 상측 누적확률, \(P(X \ge x)\): 최소 \(x\)번 성공할 확률이며, \(x\)부터 \(n\)까지의 pmf 값의 합입니다.
- 평균(기댓값), \(\mu = np\): 많은 반복에서 기대되는 성공의 평균 개수입니다.
- 분산, \(\sigma^{2}=np(1-p)\): 평균 주위의 분포의 확산입니다.
- 표준편차, \(\sigma=\sqrt{np(1-p)}\): 성공의 개수가 평균으로부터 벗어나는 전형적 크기이며, \(x\)와 같은 단위입니다.
결과 해석하기
이 계산기는 세 가지 확률과 평균을 반환합니다. 여러분의 질문 표현과 일치하는 것을 선택하세요:
- pmf, \(f(x)=P(X=x)\) — 정확히 \(x\)번 성공할 확률을 원할 때 사용합니다. 예: "10번 던져서 정확히 5번 앞면."
- 하측 누적확률, \(P(X \le x)\) — 최대 \(x\)번("\(x\)번 이하") 사용합니다. 예: "5번 이하 정답."
- 상측 누적확률, \(P(X \ge x)\) — 최소 \(x\)번("\(x\)번 이상") 사용합니다. 예: "최소 1개 불량품."
누적확률 범위는 \(x\)에서 겹친다는 점에 주목하세요: \(P(X \le x)+P(X \ge x)=1+f(x)\)는 두 범위 모두 값 \(x\) 자체를 포함하기 때문입니다. \(x\)보다 엄격히 작은 경우를 구하려면 \(P(X \le x-1)\)을 사용하고, \(x\)보다 엄격히 큰 경우를 구하려면 \(P(X \ge x+1)\)을 사용하세요.
평균 \(np\)는 성공의 기댓값입니다. 즉, 전체 \(n\)-시행 실험을 여러 번 반복했을 때의 장기 평균입니다. 정수일 필요는 없습니다. 기댓값 4.5는 단순히 평균을 나타냅니다.
모든 확률은 0과 1 사이의 소수로 보고됩니다(백분율로 하려면 100을 곱하세요). 0에 가까운 값은 사건이 드물다는 의미이고, 1에 가까운 값은 거의 확실하다는 의미입니다.
이 결과들은 네 가지 이항분포 가정이 모두 성립할 때만 유효합니다:
- 고정된 시행 횟수 \(n\), 결과를 관찰하기 전에 결정됨.
- 시행당 두 가지 결과 — 각 시행은 성공 또는 실패입니다.
- 모든 시행에서 성공의 확률 \(p\)가 일정함.
- 독립성 — 한 시행의 결과가 다른 시행에 영향을 주지 않음.
시행이 독립적이지 않거나 \(p\)가 시행 간에 변동하는 경우(예: 작은 모집단에서 복원 없이 표본추출), 이항분포 모델은 근사일 뿐입니다.
자주 묻는 질문
상측 누적확률에 x가 포함되나요? 네, 포함됩니다. 여기서 \(Q(X \ge x)\)는 \(t = x\) 지점을 포함하므로 \(P(X > x)\)가 아니라 \(P(X \ge x)\)입니다.
p=0 또는 p=1일 때는 어떻게 되나요? \(0^{0}=1\) 규약을 사용하면 \(p=0\)일 때 \(f(0)=1\)이고 나머지 확률은 모두 0이 됩니다. \(p=1\)일 때는 \(f(n)=1\)이 됩니다.
왜 '밀도'가 아니라 '확률질량'인가요? 밀도는 연속분포에 적용되는 개념입니다. 이산확률변수에서는 각 결과가 실제 확률값을 가지므로 '질량'이 올바른 표현입니다.