カイ二乗検定統計量とは?
カイ二乗(χ²)検定統計量は、観測された度数(観測度数)が、帰無仮説のもとで期待される度数(期待度数)からどれだけずれているかを表す指標です。カイ二乗適合度検定や独立性の検定の基礎となるもので、χ²の値が大きいほど観測値と期待値の差が大きいことを意味し、帰無仮説を否定する根拠となります。
この計算ツールの使い方
まず観測度数をカンマ区切りで入力し、続いて対応する期待度数を同じ順序で入力します。本ツールは各観測値とその期待値をペアにして、カテゴリーごとの寄与度を計算し、それらを合計して全体のχ²統計量を算出します。あわせて、カテゴリー数(\(k\))と自由度(\(k - 1\))も表示します。これらの値を使えば、カイ二乗分布表で臨界値やp値を調べることができます。
計算式の解説
統計量は次の式で求められます。
$$\chi^{2} = \sum_{i=1}^{k} \frac{\left(\text{O}_i - \text{E}_i\right)^{2}}{\text{E}_i}$$各カテゴリーについて、観測度数から期待度数を引き、正負の差が打ち消し合わないように二乗し、それを期待度数で割ってずれの大きさを基準化します。これらのカテゴリーごとの寄与度をすべて合計したものが検定統計量です。なお、各期待度数は0より大きくなければなりません。期待値が0のカテゴリーは、ゼロ除算を避けるためにスキップされます。
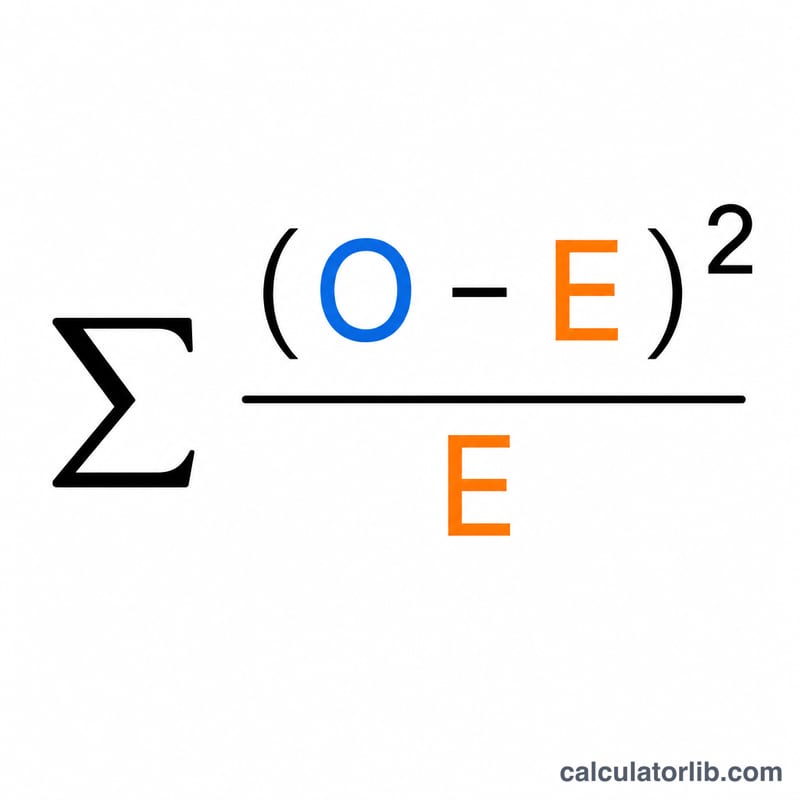
計算例
たとえば、サイコロを100回振り、観測度数が30, 20, 25, 25、各目の期待度数が等しく25ずつだったとします。各寄与度は \(\frac{(30-25)^{2}}{25} = 1\)、\(\frac{(20-25)^{2}}{25} = 1\)、\(\frac{(25-25)^{2}}{25} = 0\)、\(\frac{(25-25)^{2}}{25} = 0\) となります。これらを合計すると
$$\chi^{2} = 2.0$$カテゴリー数は4、自由度は3となります。
よくある質問
χ²が大きいと何を意味しますか? 観測データと期待データの差が大きいことを示し、帰無仮説が誤りである可能性を示唆します。
p値はどうやって求めますか? 表示された自由度を使って、カイ二乗分布に対してχ²統計量を比較します。カイ二乗分布表や統計ソフトを利用してください。
2つのリストは同じ長さである必要がありますか? はい。各観測値には対応する期待値が必要です。本ツールは入力された順序でペアにして計算します。