표본 분산이란?
표본 분산(\(s^{2}\))은 데이터가 평균을 중심으로 얼마나 퍼져 있는지를 나타내는 값입니다. 각 값과 평균 사이의 거리를 제곱해 평균을 낸 것이지만, 분모에 n 대신 n − 1을 사용한다는 점이 다릅니다. n − 1로 나누는 이유(베셀 보정)는 전체 모집단이 아니라 일부 표본만 가지고 있을 때, 실제 모집단 분산을 치우침 없이(불편) 추정하기 위해서입니다.
계산기 사용법
숫자를 쉼표나 공백으로 구분해 입력하세요. 예를 들어 4, 8, 15, 16, 23, 42처럼 넣으면 됩니다. 계산기는 표본 분산, 표본 표준편차, 평균, 개수, 편차 제곱합을 모두 보여주므로 각 단계를 직접 확인할 수 있습니다.
공식 풀이
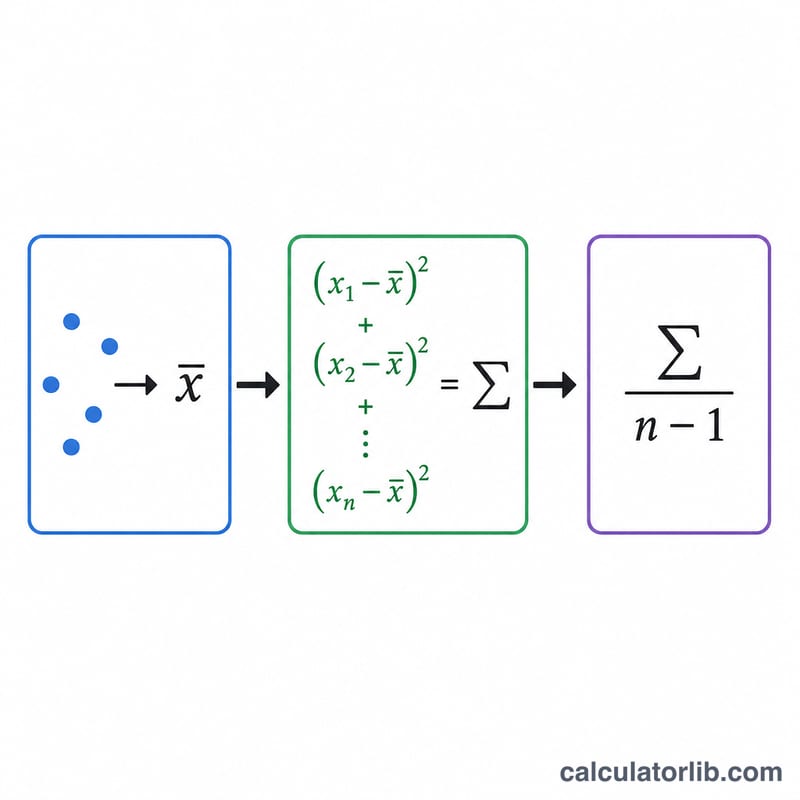
먼저 평균을 구합니다.
$$\bar{x} = \frac{1}{n}\sum_{i=1}^{n} x_i$$그다음 각 값에서 평균을 뺀 뒤 그 차이를 제곱합니다. 이 제곱값들을 모두 더하면 \(\sum_{i=1}^{n}\left(x_i - \bar{x}\right)^{2}\)가 됩니다. 마지막으로 이 합을 n − 1로 나누면 표본 분산이 나옵니다.
$$s^{2} = \frac{1}{n-1}\sum_{i=1}^{n}\left(x_i - \bar{x}\right)^{2}$$여기에 제곱근을 취하면 표본 표준편차 \(s\)를 얻을 수 있습니다.
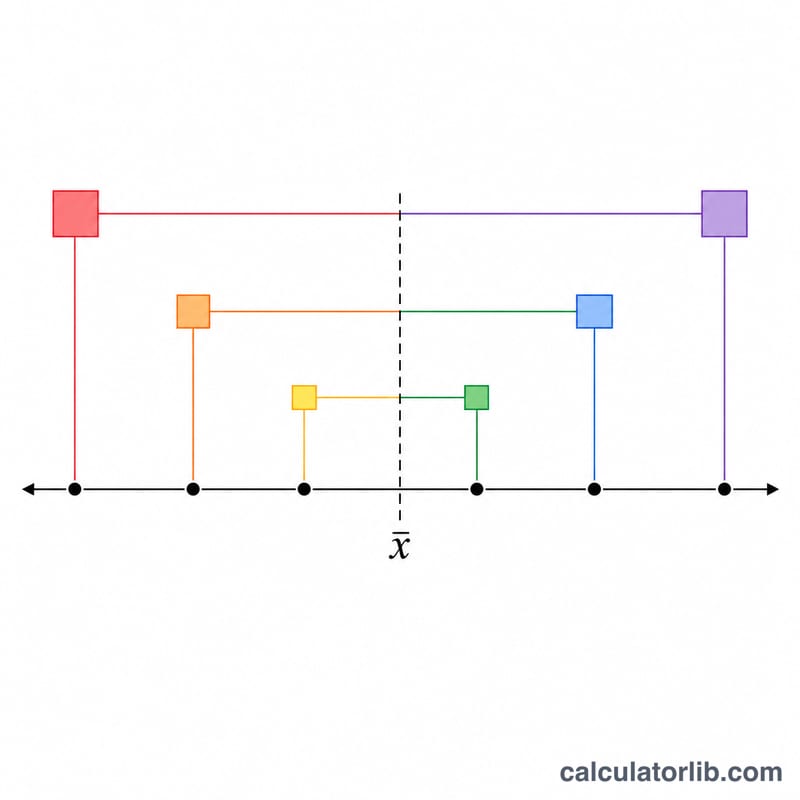
예제로 익히기
4, 8, 15, 16, 23, 42 데이터를 살펴보겠습니다. 합은 108이고 \(n = 6\)이므로 평균은 18입니다. 각 편차의 제곱은 196, 100, 9, 4, 25, 576이고, 이를 모두 더하면 910이 됩니다. 즉 \(\sum = 196+100+9+4+25+576 = 910\)이고, 분산은 \(910 / 5 = 182\)입니다. 나누기를 하기 전에 평균값이 정확한지 항상 먼저 확인하세요. 평균이 조금만 달라져도 결과가 크게 바뀔 수 있습니다.
자주 묻는 질문
왜 n이 아니라 n − 1로 나누나요? n으로 나누면 모집단의 퍼짐 정도를 실제보다 작게 추정하게 됩니다. n − 1로 나누면 이 치우침을 바로잡을 수 있습니다.
모집단 분산은 언제 사용하나요? 데이터가 표본이 아니라 모집단의 모든 구성원을 포함하고 있을 때만 모집단 분산(n으로 나눔)을 사용하세요.
분산이 크면 무슨 의미인가요? 분산이 클수록 데이터가 평균에서 더 넓게 흩어져 있다는 뜻입니다.





