표본 표준편차란?
표본 표준편차는 데이터 값들이 평균을 중심으로 얼마나 흩어져 있는지를 나타내는 지표로, 베셀 보정을 적용한 분모 \(n-1\)을 사용합니다. 분석 대상 데이터가 모집단 전체가 아니라 그 일부에서 뽑아낸 표본일 때 가장 널리 쓰이는 산포 통계량입니다.
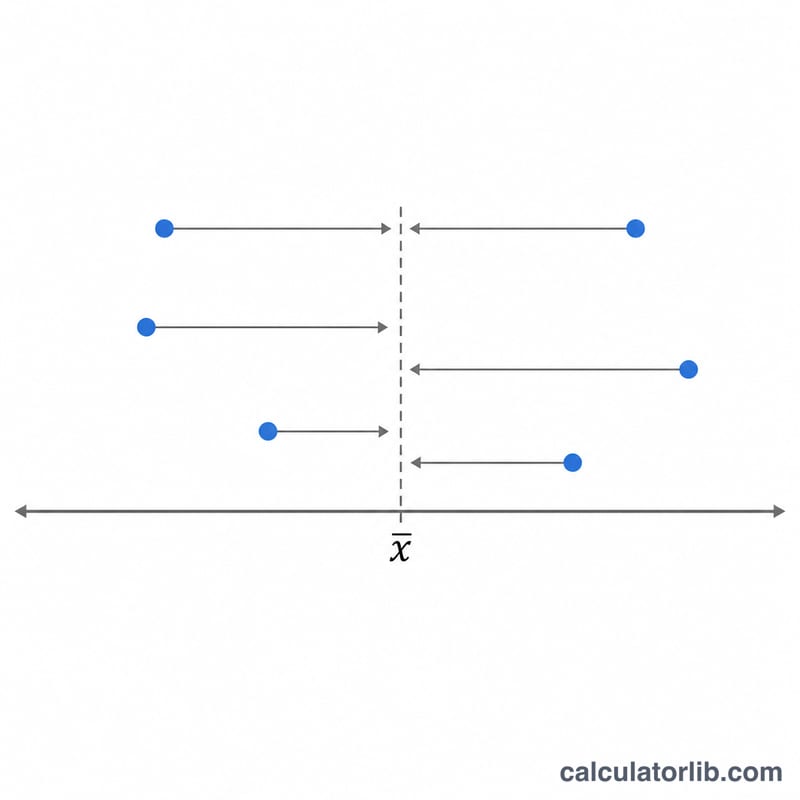
공식
\(n\)개의 값 \(x_1, x_2, \dots, x_n\)의 평균을 \(\bar{x}\)라고 할 때, 표본 표준편차 \(s\)는 다음과 같습니다.
$$s = \sqrt{\frac{1}{n-1}\sum_{i=1}^{n}(x_i-\bar{x})^2}$$여기서 \(\bar{x}=\frac{1}{n}\sum x_i\)는 평균이며, 안쪽의 합은 편차 제곱의 총합을 의미합니다.
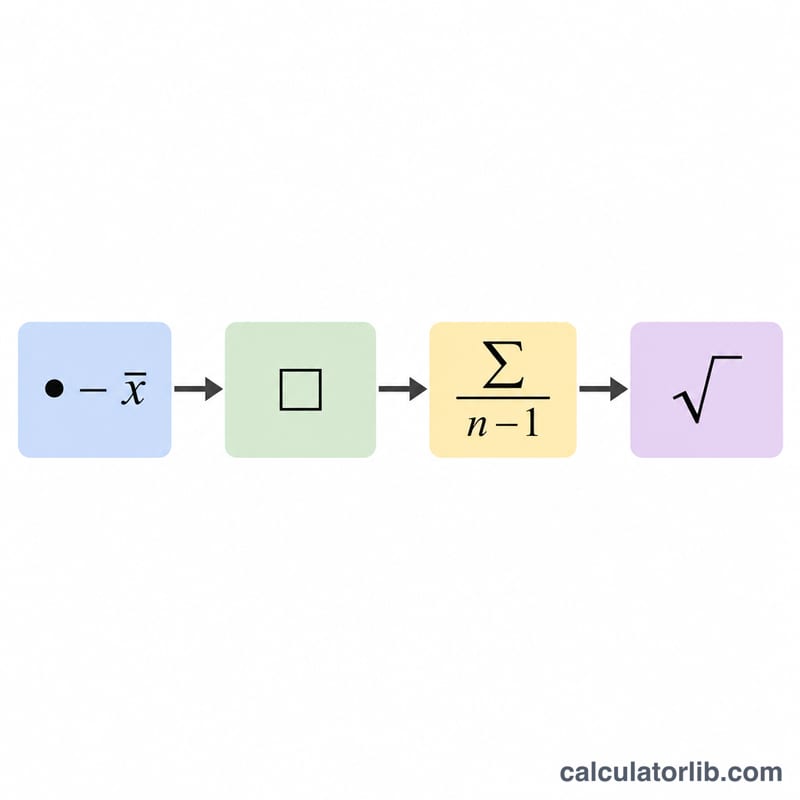
사용 방법
숫자를 쉼표나 공백으로 구분해 입력하면 표준편차, 평균, 분산, 편차 제곱합이 한눈에 표시됩니다. 표본을 다룰 때는 이 버전(n-1)을 사용하고, 모집단의 모든 구성원을 빠짐없이 가지고 있을 때만 모집단 버전(n)을 사용하세요.
계산 예시
데이터 \(2, 4, 12, 18, 24, 30\)을 살펴보겠습니다. 평균은 다음과 같습니다.
$$\bar{x}=\frac{2+4+12+18+24+30}{6}=\frac{90}{6}=15$$각 편차의 제곱은 \(169, 121, 9, 9, 81, 225\)이며, 이를 모두 더하면 다음과 같습니다.
$$\sum(x_i-\bar{x})^2 = 169+121+9+9+81+225 = 614$$따라서 분산과 표준편차는 다음과 같이 구해집니다.
$$s^2=\frac{614}{6-1}=122.8,\qquad s=\sqrt{122.8}\approx 11.08$$자주 묻는 질문
언제 n-1 대신 n으로 나누나요? \(n\)으로 나누는 경우는 모집단 표준편차를 구할 때뿐입니다. 표본일 때는 \(n-1\)을 사용해 모분산 추정의 편향을 보정합니다.
값을 하나만 입력하면 어떻게 되나요? 0으로 나누게 되어 표준편차가 정의되지 않으므로 결과는 0으로 표시됩니다.
쉼표와 공백을 섞어 써도 되나요? 네, 둘 중 어느 것으로 구분해도 됩니다. 예를 들어 4, 8 15 16처럼 입력할 수 있습니다.