합동 표준편차란?
합동 표준편차(pooled standard deviation, Sp)는 두 표본의 표준편차를 가중평균하여 하나의 값으로 합친 것으로, 두 모집단이 공통으로 갖는 모표준편차를 추정하는 데 쓰입니다. 두 독립 표본이 분산이 같은 모집단에서 나왔다고 가정할 때 사용합니다. 이 합동 추정값은 두 표본 t-검정, 효과크기 Cohen's d, 그리고 두 평균의 차이에 대한 신뢰구간을 구할 때 핵심적으로 활용됩니다.
계산기 사용 방법
각 표본의 크기(\(n_1\), \(n_2\))와 표준편차(\(s_1\), \(s_2\))를 입력하세요. 계산기는 합동 표준편차, 합동 분산(\(S_p^2\)), 그리고 자유도(\(n_1 + n_2 - 2\))를 함께 보여줍니다. 자유도가 양수가 되려면 각 표본에 적어도 2개 이상의 관측값이 있어야 합니다.
공식 풀이
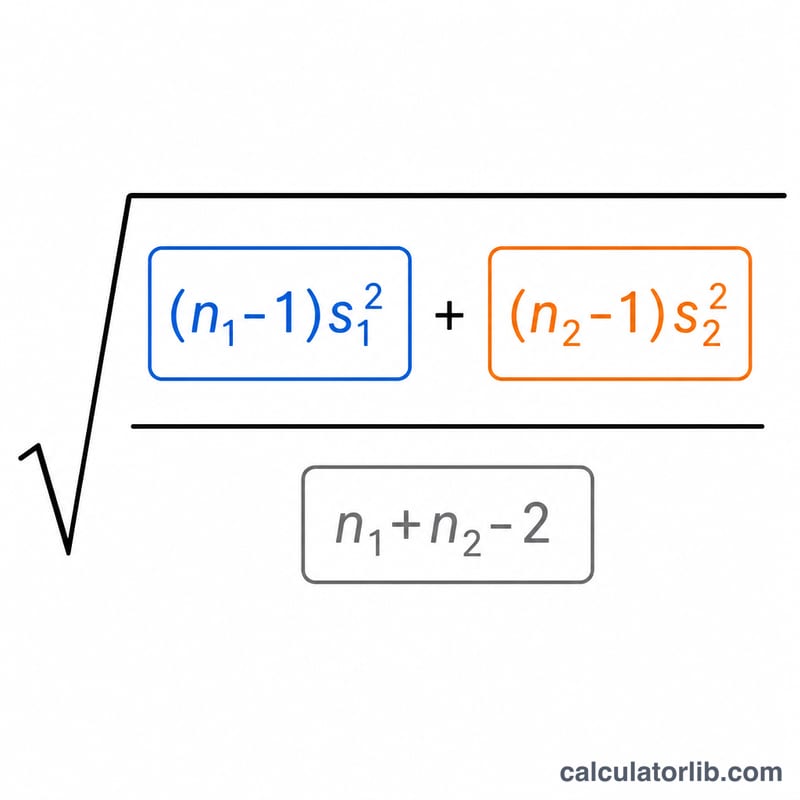
합동 분산은 각 표본의 분산을 자유도(\(n - 1\))로 가중하여 계산합니다.
$$S_p^2 = \frac{(n_1 - 1)\,s_1^{2} + (n_2 - 1)\,s_2^{2}}{n_1 + n_2 - 2}$$
여기에 제곱근을 취하면 합동 표준편차 \(S_p\)가 됩니다. 표본이 클수록 합동 추정값에 더 크게 기여하기 때문에, 단순 평균이 아니라 가중하여 분산을 계산합니다.
계산 예시
표본 1이 \(n_1 = 10\), \(s_1 = 5\)이고 표본 2가 \(n_2 = 12\), \(s_2 = 6\)이라고 합시다. 이때 \((10-1)\cdot 25 = 225\), \((12-1)\cdot 36 = 396\)이며, 둘을 더하면 \(621\)입니다. 자유도는 \(10 + 12 - 2 = 20\)이므로 $$S_p^2 = \frac{621}{20} = 31.05$$ 그리고 $$S_p = \sqrt{31.05} \approx 5.5722$$가 됩니다.
자주 묻는 질문
언제 표준편차를 합동해야 하나요? 두 집단의 모분산이 같다고 가정할 수 있을 때 합동합니다. 분산 차이가 크다면 대신 Welch's t-검정을 사용하세요.
왜 n이 아니라 n − 1을 쓰나요? \(n - 1\)(베셀 보정)을 사용하면 표본에서 모분산을 불편(unbiased) 추정할 수 있기 때문입니다.
표본의 순서가 결과에 영향을 주나요? 아닙니다. 두 표본의 순서를 바꿔도 합동 표준편차는 동일합니다.





