Что такое распределение стьюдентизированного размаха?
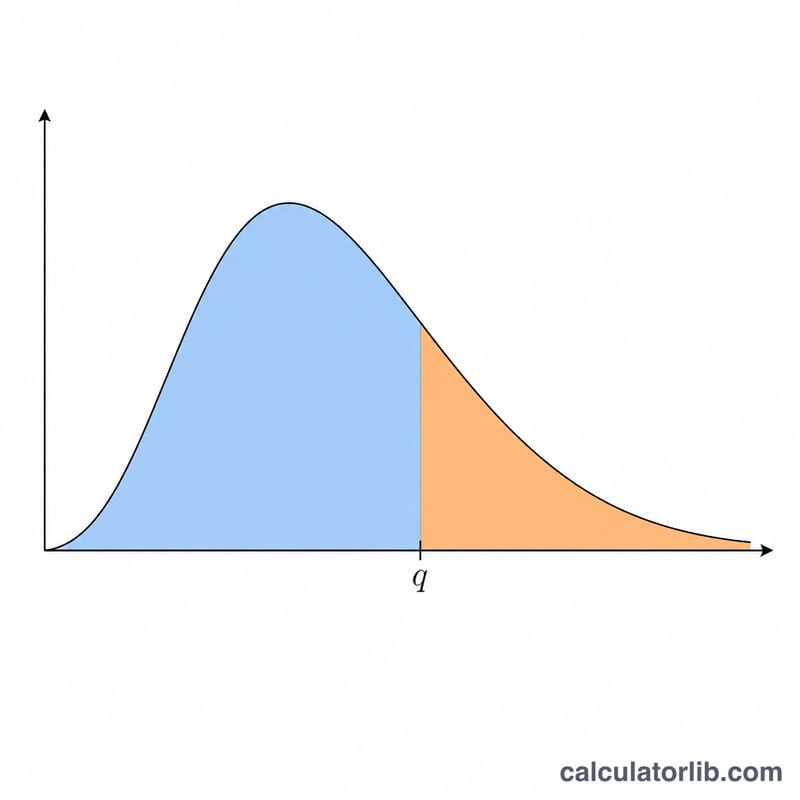
Статистика стьюдентизированного размаха q показывает, насколько разбросаны выборочные средние: это разность между наибольшим и наименьшим из r средних, делённая на независимо оценённую стандартную ошибку с ν степенями свободы. Именно на этом распределении построен критерий честно значимой разности Тьюки (Tukey HSD) и другие апостериорные (post-hoc) процедуры множественных сравнений. Калькулятор возвращает нижнюю накопленную вероятность \(P(Q \le q) = F(q, r, \nu)\) и вероятность верхнего хвоста \(P(Q > q) = 1 - F\). Это чисто статистическая функция: она применима в любой стране и не зависит от каких-либо региональных правил.
Как пользоваться калькулятором
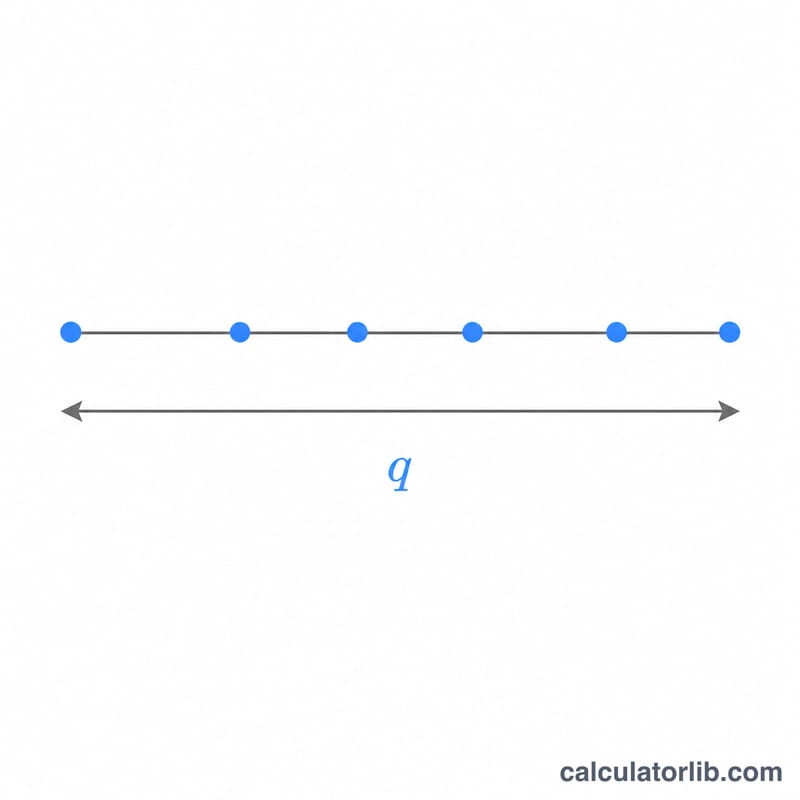
Введите четыре числа: квантиль q, в точке которого вычисляется функция распределения; объём выборки r (число сравниваемых средних в размахе, не менее 2); число степеней свободы ошибки ν и количество независимых групп c, по максимальному размаху которых ведётся расчёт. Значение \(c = 1\) соответствует обычному стьюдентизированному размаху, а \(c > 1\) моделирует максимум из c независимых экспериментов, использующих одно и то же критическое значение. Калькулятор выдаёт обе хвостовые вероятности.
Разбор формулы
Для фиксированного разброса x величина \(H(x, r)\) — это вероятность того, что размах r независимых стандартных нормальных величин не превысит x. Она вычисляется как интеграл от плотности стандартного нормального распределения, умноженной на \([\Phi(y) - \Phi(y - x)]\) в степени \(r-1\). Чтобы учесть оценённую дисперсию, выражение \(H(q\sqrt{u}, r)\) усредняется по масштабирующей плотности u (распределение хи-квадрат, делённое на ν, с ν степенями свободы) и возводится в степень c. Когда ν очень велико, дисперсия фактически известна, масштаб вырождается в \(u = 1\), и формула упрощается до $$F = [H(q, r)]^{c}.$$
Пример расчёта
При \(q = 5{,}673\), \(r = 5\), \(\nu = 5\) и \(c = 1\) калькулятор даёт нижнюю накопленную вероятность около 0,95, то есть верхний хвост составляет примерно 0,05. Это совпадает с классическим табличным критическим значением q Тьюки около 5,67 для пяти групп и пяти степеней свободы ошибки при уровне значимости \(\alpha = 0{,}05\).
Частые вопросы
Почему мой результат немного отличается от значения в печатной таблице? Вероятность находится численным интегрированием, и точность снижается при большом r и малом ν — на это указывает и исходный метод расчёта.
Зачем нужен параметр c? При \(c > 1\) вычисляется распределение максимума из c независимых стьюдентизированных размахов. Это полезно, когда одно и то же критическое значение применяется сразу к c независимым экспериментам.
Что будет, если q равно нулю или отрицательно? Размах не может быть отрицательным, поэтому \(F = 0\), а вероятность верхнего хвоста равна 1.