스튜던트화 범위 분포란?
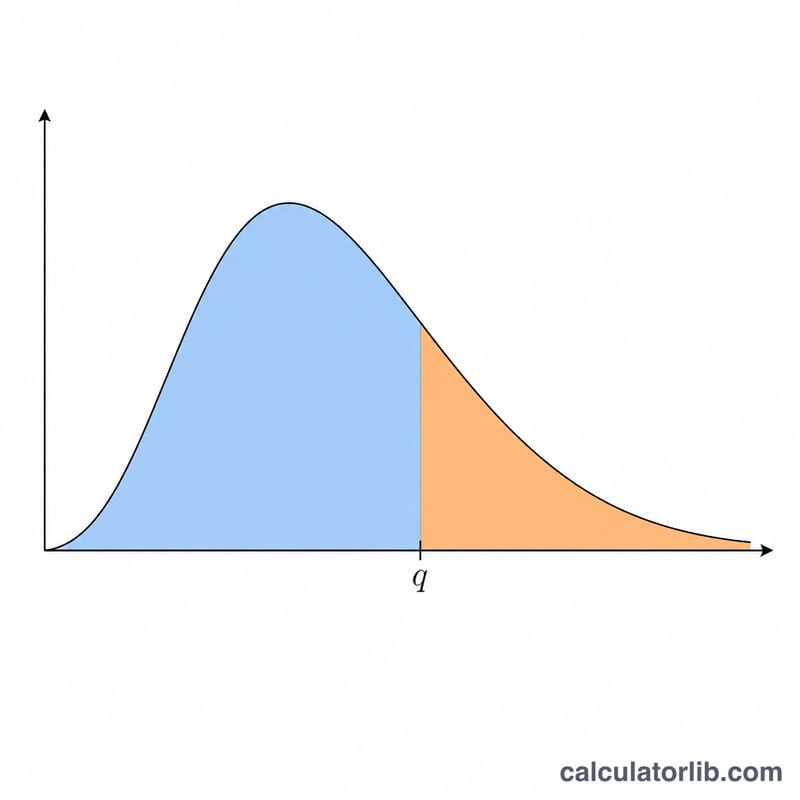
스튜던트화 범위 통계량 q는 r개 표본 평균 중 최댓값과 최솟값 사이의 폭을, 자유도 ν로 독립적으로 추정한 표준오차로 나눈 값입니다. 이 분포는 Tukey의 정직유의차(HSD) 검정을 비롯한 여러 다중비교 사후검정(post-hoc) 절차의 이론적 토대가 됩니다. 본 계산기는 하측 누적 확률 \(P(Q \le q) = F(q, r, \nu)\)와 상측 꼬리 확률 \(P(Q > q) = 1 - F\)를 함께 반환합니다. 이는 순수한 통계 함수이므로 국가나 지역에 따른 규칙 없이 어디에서나 동일하게 적용됩니다.
사용 방법
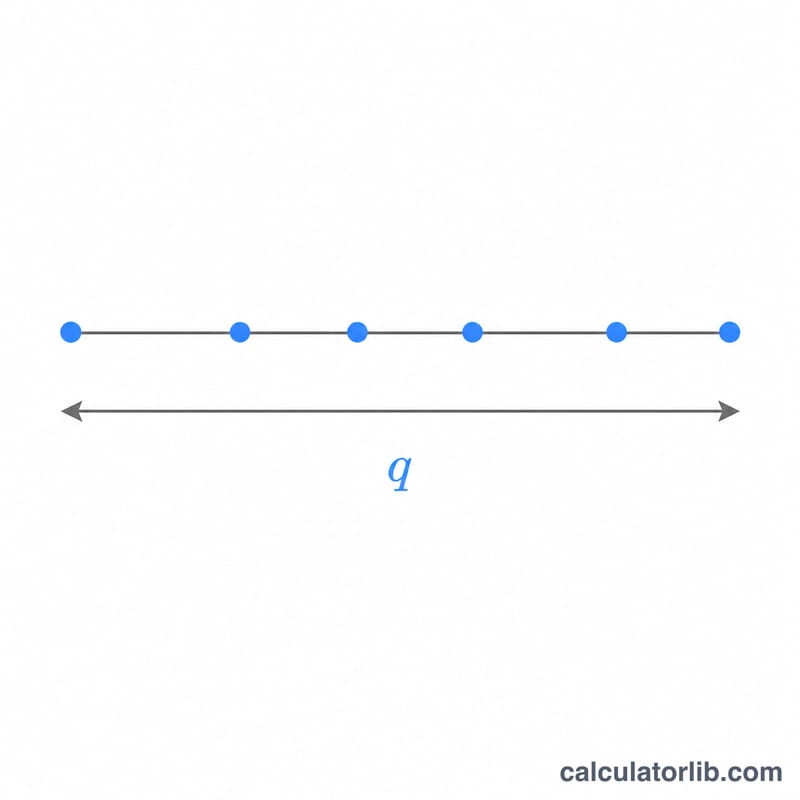
네 개의 값을 입력하세요. 누적분포함수(CDF)를 평가할 분위수 \(q\), 범위에 포함되는 처리 평균의 개수인 표본 크기 \(r\)(최소 2 이상), 오차 자유도 \(\nu\), 그리고 최대 범위를 취하는 독립 그룹의 수 \(c\)입니다. \(c = 1\)이면 일반적인 스튜던트화 범위이며, \(c > 1\)이면 하나의 임계값을 공유하는 \(c\)개의 독립 실험에서 나타나는 최댓값을 모형화합니다. 계산기는 양쪽 꼬리 확률을 모두 알려줍니다.
공식 설명
고정된 폭 \(x\)에 대해 \(H(x, r)\)은 \(r\)개의 독립적이고 동일한 표준정규 확률변수의 범위가 \(x\) 미만에 머물 확률로, 표준정규 밀도함수와 \([\Phi(y) - \Phi(y - x)]\)의 \(r-1\) 거듭제곱을 곱하여 적분한 값입니다. 추정된 분산을 반영하기 위해 \(H(q\sqrt{u}, r)\)를 자유도 \(\nu\)의 카이제곱/\(\nu\) 스케일링 밀도(변수 \(u\))에 대해 평균을 내고, 그 결과를 \(c\) 거듭제곱합니다. $$F(q;r,\nu) = \int_{0}^{\infty} \frac{\nu^{\nu/2}}{\Gamma(\nu/2)\,2^{\nu/2-1}}\, u^{\nu-1} e^{-\nu u^2/2}\,\big[H(qu,\,r)\big]^{c}\,du$$ \(\nu\)가 매우 클 때는 분산이 알려진 것으로 간주되어 스케일링이 \(u = 1\)로 수렴하며, \(F = [H(q, r)]^c\)가 됩니다. $$F(q;r) = \big[\,H\big(\text{Quantile } q,\ \text{Sample size } r\big)\,\big]^{\text{Groups } c}$$
계산 예시
\(q = 5.673\), \(r = 5\), \(\nu = 5\), \(c = 1\)을 입력하면 하측 누적 확률은 약 \(0.95\)가 되어 상측 꼬리 확률은 약 \(0.05\)입니다. 이는 다섯 개 그룹과 오차 자유도 5, 유의수준 \(\alpha = 0.05\)에 대해 전통적인 Tukey q 표의 임계값이 약 \(5.67\)인 것과 일치합니다.
자주 묻는 질문
인쇄된 표의 값과 결과가 조금 다른 이유는? 확률은 수치 적분으로 구하기 때문에, 원 알고리즘에서도 언급하듯 \(r\)이 크고 \(\nu\)가 작을 때 정확도가 다소 떨어질 수 있습니다.
c는 어떤 역할을 하나요? \(c > 1\)은 \(c\)개의 독립적인 스튜던트화 범위 중 최댓값의 분포를 나타냅니다. 동일한 임계값을 \(c\)개의 독립 실험에 반복 적용할 때 유용합니다.
q가 0이거나 음수이면 어떻게 되나요? 범위는 음수가 될 수 없으므로 \(F = 0\)이며, 상측 확률은 1이 됩니다.