Qu'est-ce que la loi de l'étendue studentisée ?
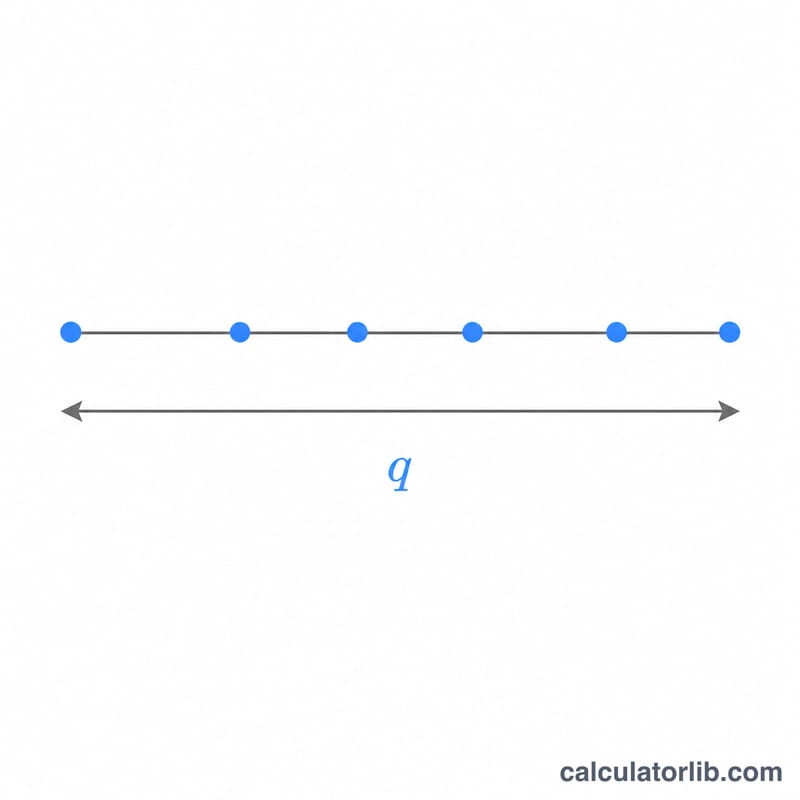
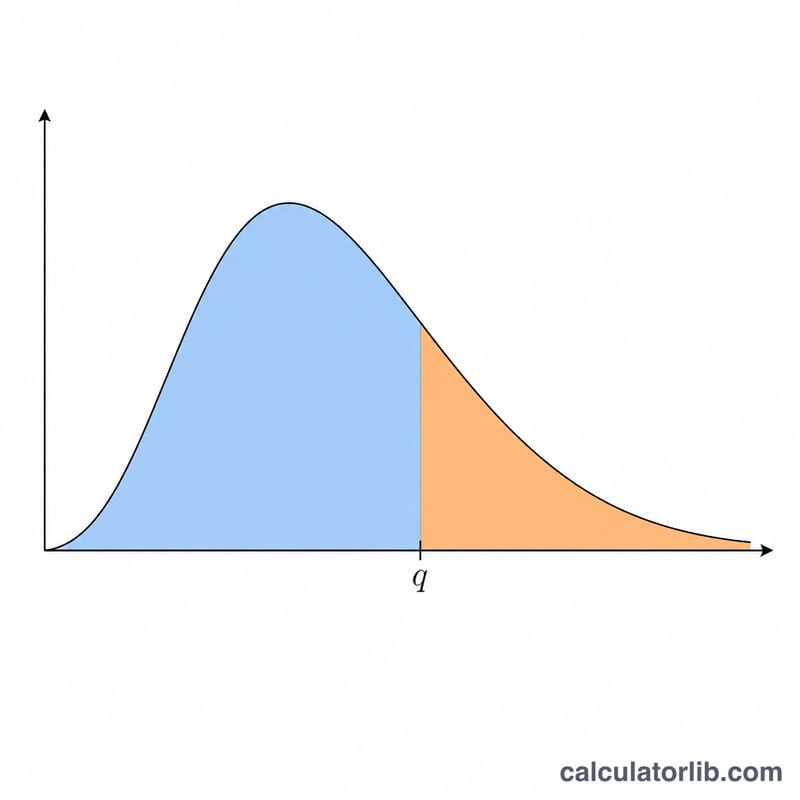
La statistique de l'étendue studentisée \(q\) mesure l'écart entre la plus grande et la plus petite de \(r\) moyennes d'échantillon, divisé par une erreur-type estimée de façon indépendante avec \(\nu\) degrés de liberté. Sa distribution est au cœur du test de Tukey (différence honnêtement significative, ou HSD) ainsi que d'autres procédures post-hoc de comparaisons multiples. Ce calculateur renvoie la probabilité cumulée inférieure \(P(Q \le q) = F(q, r, \nu)\) et la queue supérieure \(P(Q > q) = 1 - F\). Il s'agit d'une fonction purement statistique, d'application universelle, sans aucune règle propre à un pays.
Comment l'utiliser
Saisissez quatre valeurs : le quantile \(q\) auquel évaluer la fonction de répartition, l'effectif \(r\) (nombre de moyennes de traitement comprises dans l'étendue, au minimum 2), les degrés de liberté de l'erreur \(\nu\), et le nombre de groupes indépendants \(c\) dont on retient l'étendue maximale (\(c = 1\) correspond à l'étendue studentisée classique ; \(c > 1\) modélise le maximum de \(c\) expériences indépendantes partageant une même valeur critique). L'outil affiche les deux probabilités de queue.
La formule expliquée
Pour un écart fixé \(x\), \(H(x, r)\) représente la probabilité que l'étendue de \(r\) variables normales centrées réduites indépendantes reste inférieure à \(x\). Elle se calcule comme l'intégrale de la densité normale standard multipliée par \([\Phi(y) - \Phi(y - x)]\) élevé à la puissance \(r-1\). Pour tenir compte de la variance estimée, \(H(q\sqrt{u}, r)\) est moyenné par rapport à la densité de mise à l'échelle du khi-deux\(/\nu\) de \(u\) (avec \(\nu\) degrés de liberté), puis élevé à la puissance \(c\). La fonction de répartition complète s'écrit :
$$F(q;r,\nu) = \int_{0}^{\infty} \frac{\nu^{\nu/2}}{\Gamma(\nu/2)\,2^{\nu/2-1}}\, u^{\nu-1} e^{-\nu u^2/2}\,\big[H(qu,\,r)\big]^{c}\,du$$Lorsque \(\nu\) est extrêmement grand, la variance est connue, la mise à l'échelle se réduit à \(u = 1\), et :
$$F = \big[H(q, r)\big]^{c}$$Exemple résolu
Avec \(q = 5{,}673\), \(r = 5\), \(\nu = 5\) et \(c = 1\), le calculateur renvoie une probabilité cumulée inférieure d'environ \(0{,}95\) ; la queue supérieure vaut donc environ \(0{,}05\). Ce résultat correspond à la valeur critique classique de la table \(q\) de Tukey, soit environ \(5{,}67\) pour cinq groupes et cinq degrés de liberté de l'erreur au seuil \(\alpha = 0{,}05\).
FAQ
Pourquoi mon résultat diffère-t-il légèrement d'une table imprimée ? La probabilité est obtenue par intégration numérique ; la précision se dégrade lorsque \(r\) est grand et \(\nu\) petit, comme le signale la méthode de référence.
À quoi sert \(c\) ? Avec \(c > 1\), on obtient la distribution du maximum de \(c\) étendues studentisées indépendantes, ce qui est utile lorsqu'une même valeur critique est réutilisée dans \(c\) expériences indépendantes.
Et si \(q\) est nul ou négatif ? Une étendue ne peut pas être négative : on a donc \(F = 0\) et la probabilité supérieure vaut \(1\).