स्टूडेंटाइज़्ड रेंज वितरण क्या है?
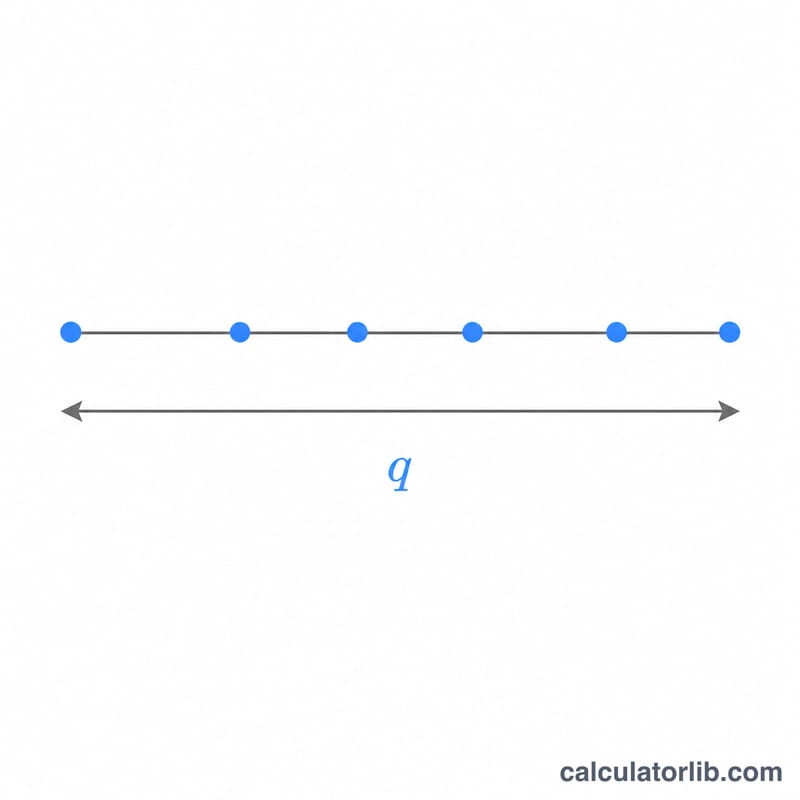
स्टूडेंटाइज़्ड रेंज सांख्यिकी \(q\), \(r\) सैंपल माध्यों में से सबसे बड़े और सबसे छोटे के बीच के अंतर को मापती है, जिसे \(\nu\) स्वतंत्रता की कोटि (degrees of freedom) वाली एक स्वतंत्र रूप से आकलित मानक त्रुटि (standard error) से भाग दिया जाता है। इसी वितरण पर Tukey का Honestly Significant Difference (HSD) परीक्षण और अन्य मल्टीपल-कम्पैरिज़न पोस्ट-हॉक विधियाँ आधारित हैं। यह कैलकुलेटर निचली संचयी प्रायिकता \(P(Q \le q) = F(q, r, \nu)\) और ऊपरी पुच्छ (upper tail) \(P(Q > q) = 1 - F\) दोनों लौटाता है। यह एक शुद्ध सांख्यिकीय फ␣लन है, जो हर जगह समान रूप से लागू होता है — इसमें किसी देश या क्षेत्र विशेष के नियम शामिल नहीं हैं।
इसका उपयोग कैसे करें
चार संख्याएँ दर्ज करें: वह क्वांटाइल \(q\) जिस पर CDF का मूल्यांकन करना है; सैंपल साइज़ \(r\) (रेंज में शामिल ट्रीटमेंट माध्यों की संख्या, कम से कम 2); त्रुटि की स्वतंत्रता कोटि \(\nu\); और स्वतंत्र समूहों की संख्या \(c\) जिनकी अधिकतम रेंज ली जाती है (\(c = 1\) साधारण स्टूडेंटाइज़्ड रेंज है; \(c > 1\) उन \(c\) स्वतंत्र प्रयोगों के अधिकतम का मॉडल बनाता है जो एक ही क्रांतिक मान साझा करते हैं)। टूल दोनों पुच्छ प्रायिकताएँ बताता है।
सूत्र की व्याख्या
किसी निश्चित विस्तार \(x\) के लिए, \(H(x, r)\) इस बात की प्रायिकता है कि \(r\) स्वतंत्र समान-वितरित (iid) मानक प्रसामान्य मानों की रेंज \(x\) से नीचे रहे। इसे मानक प्रसामान्य घनत्व और \([\Phi(y) - \Phi(y - x)]\) को घात \(r-1\) तक उठाकर उनके गुणनफल के समाकलन (integral) के रूप में निकाला जाता है। आकलित प्रसरण (variance) को ध्यान में रखने के लिए, \(H(q\sqrt{u}, r)\) को \(u\) के काई-वर्ग/\(\nu\) स्केलिंग घनत्व (\(\nu\) स्वतंत्रता कोटि के साथ) के सापेक्ष औसत निकाला जाता है और फिर घात \(c\) तक उठाया जाता है। पूरा सूत्र इस प्रकार है:
$$F(q;r,\nu) = \int_{0}^{\infty} \frac{\nu^{\nu/2}}{\Gamma(\nu/2)\,2^{\nu/2-1}}\, u^{\nu-1} e^{-\nu u^2/2}\,\big[H(qu,\,r)\big]^{c}\,du$$जब \(\nu\) अत्यधिक बड़ा हो तो प्रसरण ज्ञात होता है, स्केलिंग सिमटकर \(u = 1\) हो जाती है, और
$$F(q;r) = \big[\,H\big(\text{Quantile } q,\ \text{Sample size } r\big)\,\big]^{\text{Groups } c}$$बन जाता है।
हल किया हुआ उदाहरण
\(q = 5.673\), \(r = 5\), \(\nu = 5\), \(c = 1\) के साथ कैलकुलेटर लगभग \(0.95\) की निचली संचयी प्रायिकता लौटाता है, यानी ऊपरी पुच्छ करीब \(0.05\) है। यह पाँच समूहों और पाँच त्रुटि स्वतंत्रता कोटियों के लिए \(\alpha = 0.05\) पर लगभग \(5.67\) के क्लासिक Tukey \(q\)-टेबल क्रांतिक मान से मेल खाता है।
अक्सर पूछे जाने वाले प्रश्न
मेरा उत्तर छपी हुई टेबल से थोड़ा अलग क्यों आता है? प्रायिकता संख्यात्मक समाकलन (numerical integration) से निकाली जाती है; जैसा कि स्रोत विधि बताती है, जब \(r\) बड़ा और \(\nu\) छोटा हो तो सटीकता घट जाती है।
\(c\) क्या करता है? \(c > 1\) से \(c\) स्वतंत्र स्टूडेंटाइज़्ड रेंजों के अधिकतम का वितरण मिलता है, जो तब उपयोगी है जब एक ही क्रांतिक मान \(c\) स्वतंत्र प्रयोगों में दोबारा इस्तेमाल किया जाता है।
अगर \(q\) शून्य या ऋणात्मक हो तो? रेंज कभी ऋणात्मक नहीं हो सकती, इसलिए \(F = 0\) और ऊपरी प्रायिकता 1 होती है।