Phân phối khoảng studentized là gì?
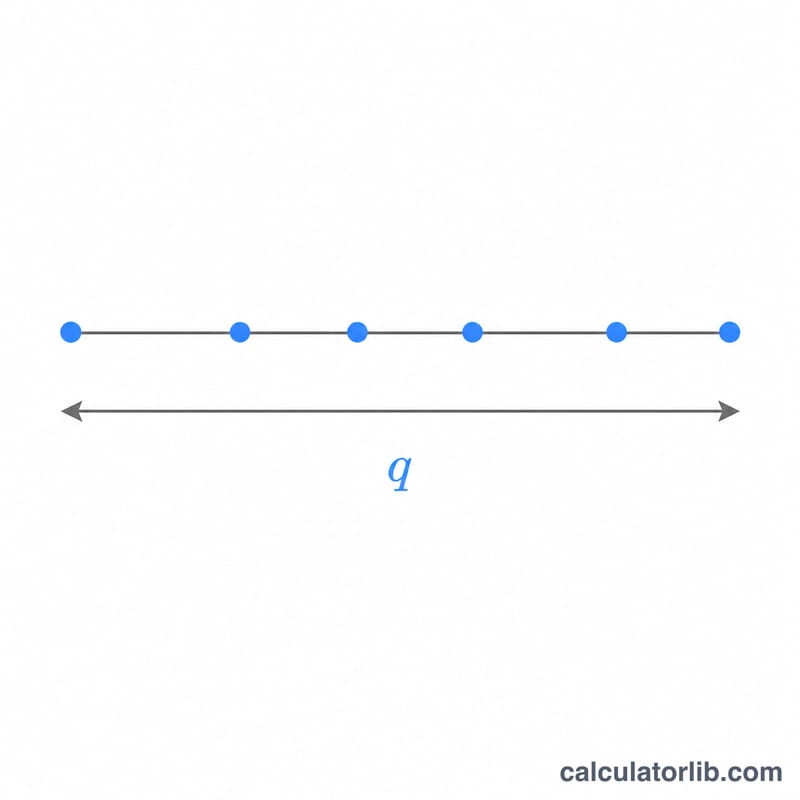
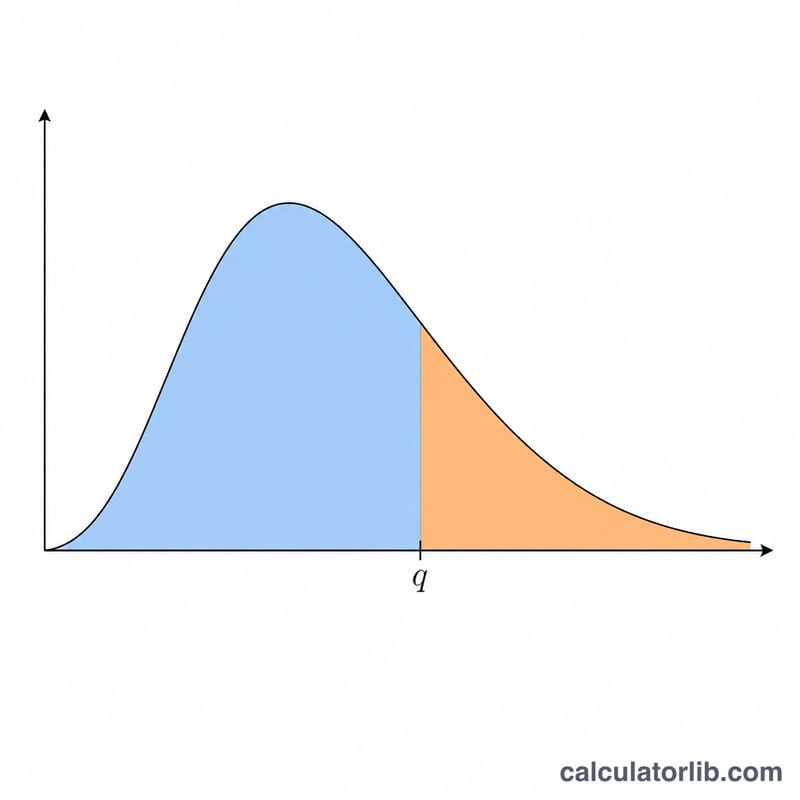
Thống kê khoảng studentized q đo độ chênh lệch giữa trung bình mẫu lớn nhất và nhỏ nhất trong số r trung bình mẫu, chia cho sai số chuẩn được ước lượng độc lập với ν bậc tự do. Phân phối này là nền tảng cho kiểm định Sự Khác Biệt Có Ý Nghĩa Thực Sự (HSD) của Tukey cùng nhiều thủ tục so sánh bội (post-hoc) khác. Máy tính này trả về xác suất tích lũy phía dưới \(P(Q \le q) = F(q, r, \nu)\) và đuôi trên \(P(Q > q) = 1 - F\). Đây là một hàm thống kê thuần túy, áp dụng được ở mọi nơi và không phụ thuộc quy định của riêng quốc gia nào.
Cách sử dụng
Bạn nhập bốn con số: phân vị \(q\) là điểm cần tính hàm phân phối tích lũy (CDF), cỡ mẫu \(r\) (số trung bình của các nhóm điều trị trong khoảng, tối thiểu là 2), bậc tự do của sai số \(\nu\), và số nhóm độc lập \(c\) mà ta lấy khoảng cực đại (\(c = 1\) là khoảng studentized thông thường; \(c > 1\) mô hình hóa giá trị cực đại của c thí nghiệm độc lập cùng dùng chung một giá trị tới hạn). Công cụ sẽ báo cáo cả hai xác suất đuôi.
Giải thích công thức
Với một độ chênh \(x\) cố định, \(H(x, r)\) là xác suất để khoảng của r biến chuẩn tắc độc lập cùng phân phối nằm dưới \(x\), được tính bằng tích phân của mật độ chuẩn tắc nhân với \([\Phi(y) - \Phi(y - x)]\) lũy thừa r−1. Để tính đến phương sai được ước lượng, \(H(q\sqrt{u}, r)\) được lấy trung bình theo mật độ tỷ lệ chi-bình-phương/ν của \(u\) (với ν bậc tự do) rồi nâng lên lũy thừa c. $$F(q;r,\nu) = \int_{0}^{\infty} \frac{\nu^{\nu/2}}{\Gamma(\nu/2)\,2^{\nu/2-1}}\, u^{\nu-1} e^{-\nu u^2/2}\,\big[H(qu,\,r)\big]^{c}\,du$$ Khi ν cực kỳ lớn, phương sai coi như đã biết, hệ số tỷ lệ thu về \(u = 1\), và $$F = \big[H(q, r)\big]^{c}$$
Ví dụ minh họa
Với \(q = 5{,}673\), \(r = 5\), \(\nu = 5\), \(c = 1\), máy tính trả về xác suất tích lũy phía dưới khoảng \(0{,}95\), nên đuôi trên xấp xỉ \(0{,}05\). Kết quả này khớp với giá trị tới hạn cổ điển trong bảng q Tukey vào khoảng \(5{,}67\) cho năm nhóm và năm bậc tự do sai số ở mức ý nghĩa \(\alpha = 0{,}05\).
Câu hỏi thường gặp
Vì sao kết quả của tôi lệch nhẹ so với bảng in sẵn? Xác suất được tìm bằng tích phân số; độ chính xác giảm khi r lớn và ν nhỏ, đúng như phương pháp gốc đã lưu ý.
c có tác dụng gì? \(c > 1\) cho phân phối của giá trị cực đại của c khoảng studentized độc lập, hữu ích khi cùng một giá trị tới hạn được dùng lại trên c thí nghiệm độc lập.
Nếu q bằng 0 hoặc âm thì sao? Một khoảng không thể âm, nên \(F = 0\) và xác suất phía trên bằng 1.