什麼是司徒頓化全距分配?
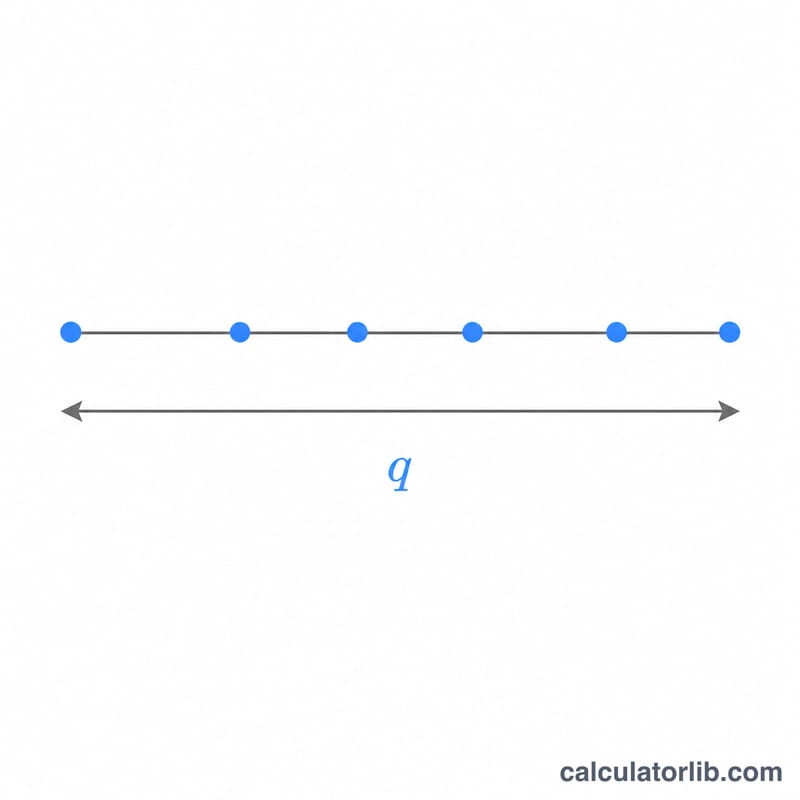
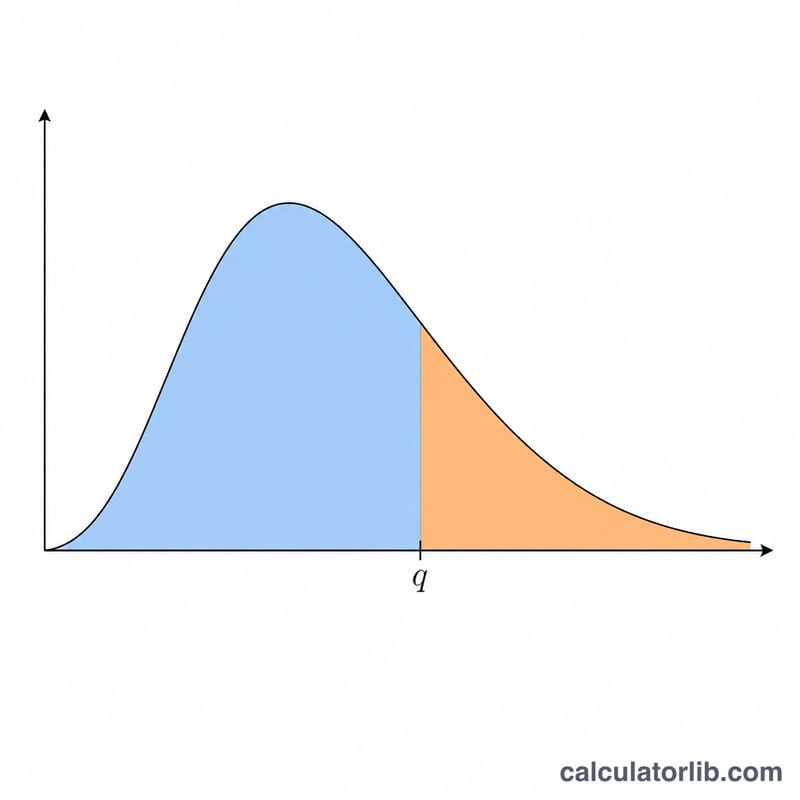
司徒頓化全距統計量 \(q\),衡量的是 \(r\) 個樣本平均數中最大值與最小值之間的差距,再除以一個獨立估計、具有 \(\nu\) 自由度的標準誤。這個分配正是 Tukey 誠實顯著差異檢定(HSD)以及其他多重比較事後檢定的理論基礎。本計算器會回傳下尾累積機率 \(P(Q \le q) = F(q, r, \nu)\) 與上尾機率 \(P(Q > q) = 1 - F\)。它純粹是一個統計函數,全球通用,不受任何地區規則影響。
如何使用
請輸入四個數值:要評估 CDF 的分位數 \(q\)、全距所涵蓋的樣本數 \(r\)(也就是參與比較的處理平均數個數,至少為 2)、誤差自由度 \(\nu\),以及取最大全距的獨立組數 \(c\)(當 \(c = 1\) 時即為一般的司徒頓化全距;\(c > 1\) 則用來模擬 \(c\) 個獨立實驗共用同一臨界值時取最大值的情況)。計算器會同時顯示兩側的尾端機率。
公式說明
對於固定的差距 \(x\),\(H(x, r)\) 表示 \(r\) 個獨立同分配標準常態變數的全距小於 \(x\) 的機率,計算方式是將標準常態密度乘以 \([\Phi(y) - \Phi(y - x)]\) 的 \(r-1\) 次方後進行積分。為了納入估計變異數的影響,再把 \(H(q\sqrt{u}, r)\) 對 \(u\) 的卡方/\(\nu\) 縮放密度(自由度為 \(\nu\))取加權平均,並提升到 \(c\) 次方。 $$F(q;r,\nu) = \int_{0}^{\infty} \frac{\nu^{\nu/2}}{\Gamma(\nu/2)\,2^{\nu/2-1}}\, u^{\nu-1} e^{-\nu u^2/2}\,\big[H(qu,\,r)\big]^{c}\,du$$ 當 \(\nu\) 極大時,變異數視為已知,縮放因子收斂為 \(u = 1\),此時 $$F = \big[H(q, r)\big]^{c}.$$
範例演算
當 \(q = 5.673\)、\(r = 5\)、\(\nu = 5\)、\(c = 1\) 時,計算器回傳的下尾累積機率約為 \(0.95\),因此上尾機率約為 \(0.05\)。這與經典 Tukey \(q\) 表中「五組、五個誤差自由度、\(\alpha = 0.05\)」對應的臨界值約 \(5.67\) 相符。
常見問題
為什麼我算出來的結果和書上印的表格略有出入?本機率是以數值積分求得的;正如原始演算法所述,當 \(r\) 較大而 \(\nu\) 較小時,精確度會略為下降。
\(c\) 的作用是什麼?\(c > 1\) 給出的是 \(c\) 個獨立司徒頓化全距取最大值的分配,常用於在 \(c\) 個獨立實驗中重複套用同一臨界值的情況。
如果 \(q\) 等於零或為負數會怎樣?全距不可能為負,因此 \(F = 0\),上尾機率為 \(1\)。