ステューデント化された範囲とは
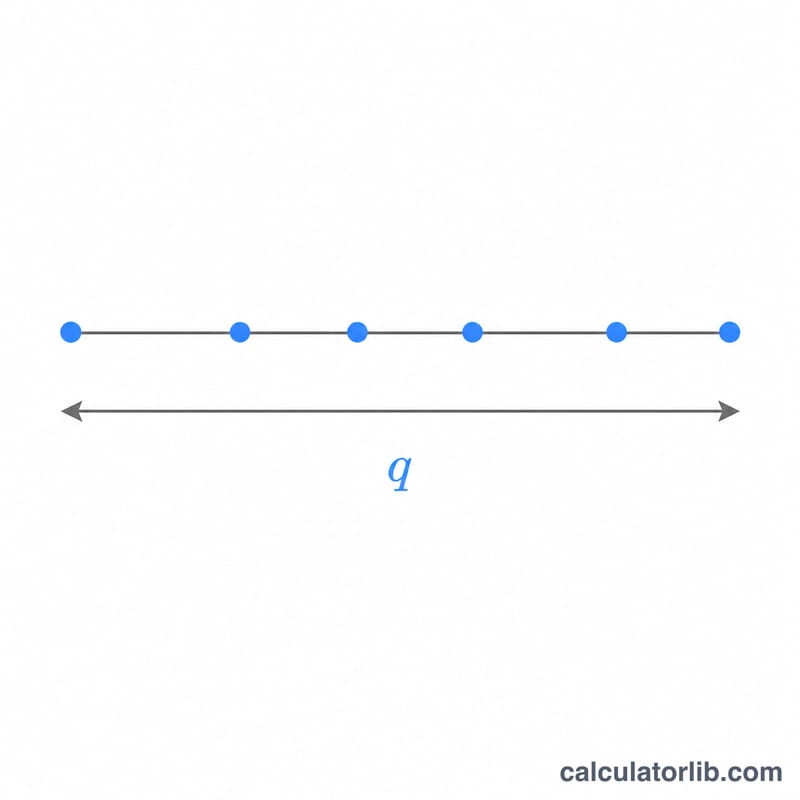
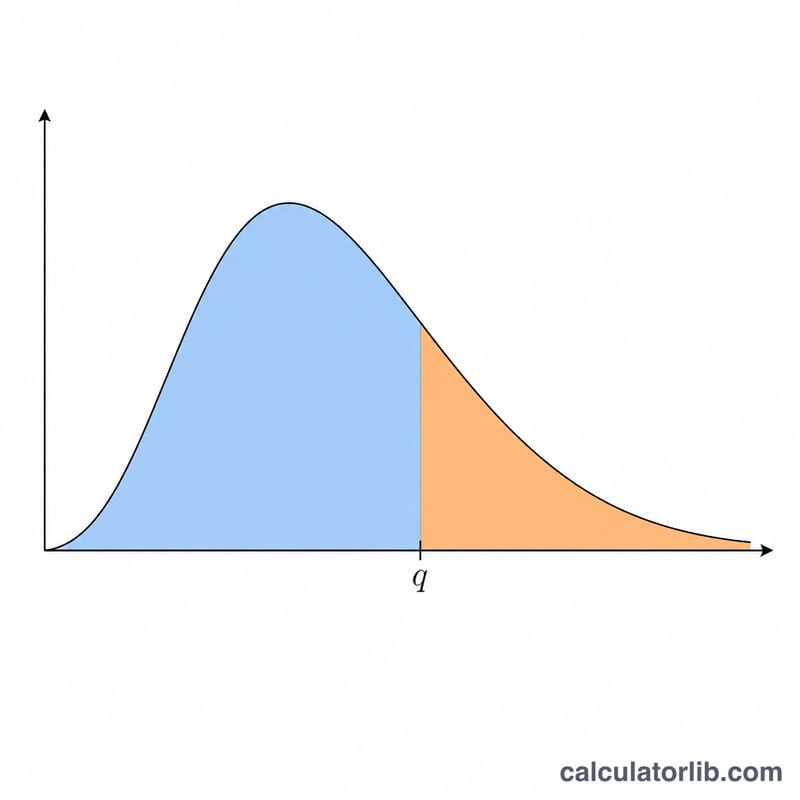
ステューデント化された範囲統計量 \(q\) は、\(r\) 個の標本平均のうち最大値と最小値の差(範囲)を、自由度 \(\nu\) をもつ独立に推定された標準誤差で割った量です。この分布は、テューキーのHSD検定(Honestly Significant Difference、有意差検定)をはじめとする多重比較の事後検定の理論的な土台となっています。本ツールでは、下側累積確率 \(P(Q \le q) = F(q, r, \nu)\) と上側確率 \(P(Q > q) = 1 - F\) を求めます。純粋な統計関数であり、国や地域に依存するルールはなく、どこでも共通に利用できます。
使い方
次の4つの数値を入力します。累積分布関数を評価する分位点 \(q\)、範囲を構成する標本数 \(r\)(比較する平均の個数で、2以上)、誤差の自由度 \(\nu\)、そして最大範囲をとる独立な群の数 \(c\) です。\(c = 1\) のときは通常のステューデント化された範囲となり、\(c > 1\) のときは同一の臨界値を共有する \(c\) 個の独立した実験のうちの最大値をモデル化します。ツールは下側・上側の両方の確率を出力します。
計算式の解説
ある範囲 \(x\) を固定したとき、\(H(x, r)\) は \(r\) 個の独立同分布の標準正規変数の範囲が \(x\) 未満に収まる確率で、標準正規密度に \([\Phi(y) - \Phi(y - x)]\) を \(r-1\) 乗したものを掛けて積分することで求めます。推定された分散を考慮するため、\(H(q\sqrt{u}, r)\) を自由度 \(\nu\) のカイ二乗/\(\nu\) のスケーリング密度(変数 \(u\))について平均し、さらに \(c\) 乗します。\(\nu\) が非常に大きい場合は分散が既知とみなせ、スケーリングは \(u = 1\) に収束して $$F = [H(q, r)]^{c}$$ となります。
$$F(q;r,\nu) = \int_{0}^{\infty} \frac{\nu^{\nu/2}}{\Gamma(\nu/2)\,2^{\nu/2-1}}\, u^{\nu-1} e^{-\nu u^2/2}\,\big[H(qu,\,r)\big]^{c}\,du$$計算例
\(q = 5.673\)、\(r = 5\)、\(\nu = 5\)、\(c = 1\) とすると、下側累積確率は約 \(0.95\) となり、上側確率は約 \(0.05\) となります。これは、群数5・誤差自由度5・有意水準 \(\alpha = 0.05\) におけるテューキーの \(q\) 表の臨界値(およそ \(5.67\))とよく一致します。
よくある質問
印刷された数表と答えがわずかに異なるのはなぜですか。 確率は数値積分によって求めているためです。元の計算手法でも指摘されているとおり、\(r\) が大きく \(\nu\) が小さい場合は精度が低下します。
c は何を表しますか。 \(c > 1\) は、\(c\) 個の独立したステューデント化された範囲の最大値の分布を与えます。同じ臨界値を \(c\) 個の独立した実験で繰り返し用いる場合に役立ちます。
q がゼロや負の場合はどうなりますか。 範囲は負になり得ないため、\(F = 0\) となり、上側確率は \(1\) になります。