この計算ツールでできること
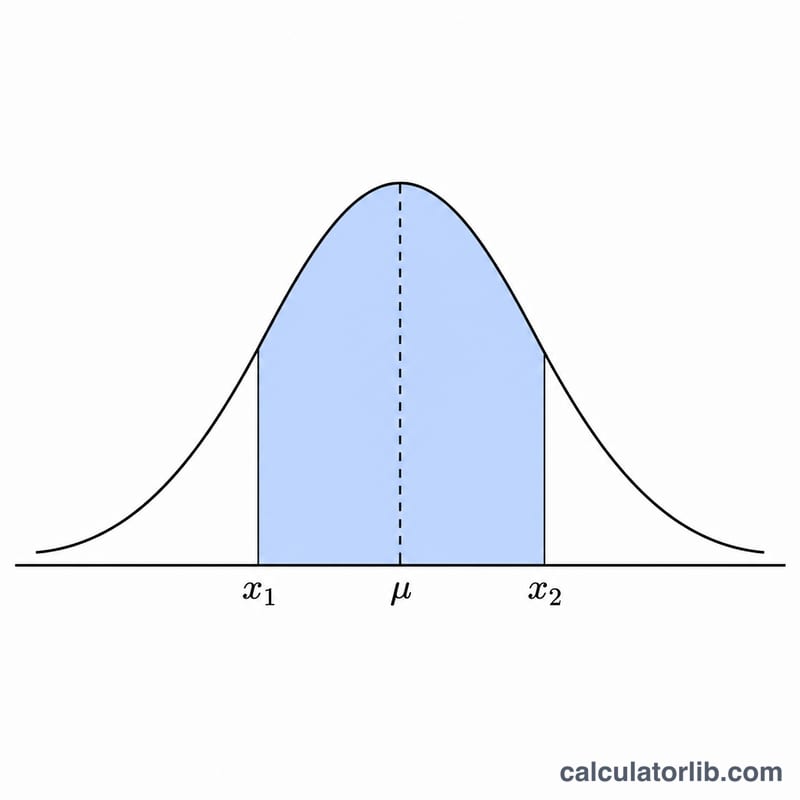
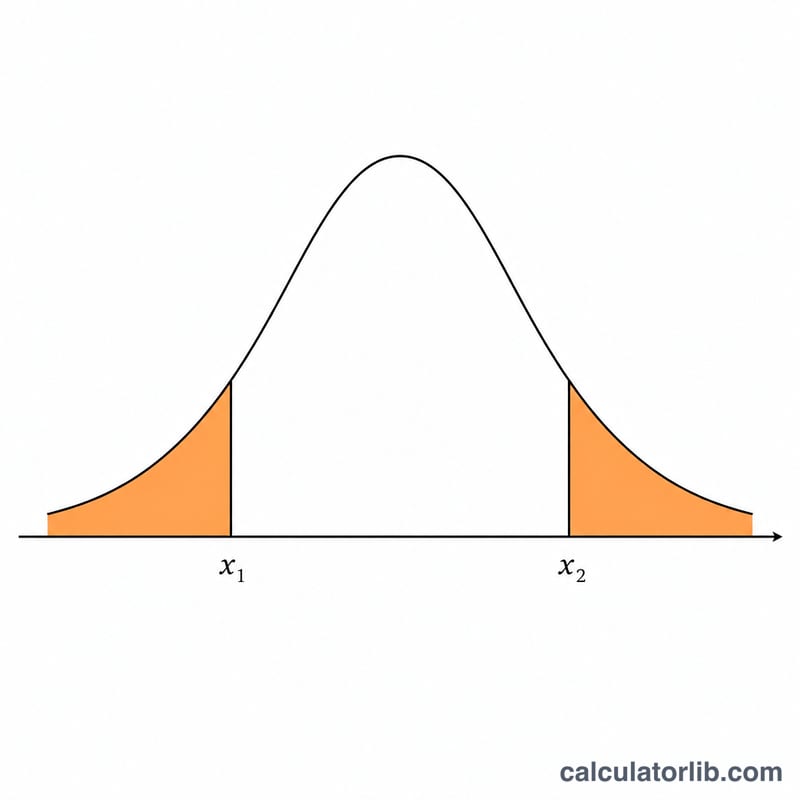
このツールは、平均\(\mu\)と標準偏差\(\sigma\)で定まる正規分布(ガウス分布)\(N(\mu, \sigma^2)\)を扱います。2つの点x1とx2を入力すると、次の4つの値が求められます。各点における確率密度f(x1)とf(x2)、2点の間の面積にあたる内側累積確率\(P(\text{x}_1 \le X \le \text{x}_2)\)、そして両側の裾(すそ)にあたる外側累積確率(内側の面積を1から引いた値)です。地域や国ごとのルールは一切関係しない純粋な数学・統計ツールなので、どこの国の方でもそのまま利用できます。
使い方
2つの点x1とx2を入力します(小さいほうが自動的に下限として扱われます)。続いて平均\(\mu\)と標準偏差\(\sigma\)を入力してください。初期値の\(\mu=0\)、\(\sigma=1\)は標準正規分布を表し、このときx の値はそのままz値(zスコア)として読み取れます。標準偏差は必ず0より大きい値を指定してください。
計算式の解説
各点はまずz値 \(z = \dfrac{x - \mu}{\sigma}\) に変換されます。確率密度は $$f(x) = \frac{1}{\sigma\sqrt{2\pi}}\; e^{-\frac{\left(x - \mu\right)^2}{2\,\sigma^2}}$$ で求めます。累積面積には標準正規分布の累積分布関数(CDF) \(\Phi(z) = \tfrac{1}{2}\left(1 + \operatorname{erf}\!\left(\tfrac{z}{\sqrt{2}}\right)\right)\) を用います。Javaには誤差関数erfが標準で用意されていないため、Abramowitz & Stegunの近似式7.1.26(精度およそ1e-7)を使用しています。内側確率は \(\Phi(z_2) - \Phi(z_1)\)、外側確率はそれを1から引いた値となります。 $$P(\,\text{x}_1 \le X \le \text{x}_2\,) = \Phi(z_2) - \Phi(z_1)$$ $$\text{where}\quad \left\{ \begin{aligned} z_1 &= \dfrac{\text{x}_1 - \mu}{\sigma} \\ z_2 &= \dfrac{\text{x}_2 - \mu}{\sigma} \\ \Phi(z) &= \tfrac{1}{2}\left(1 + \operatorname{erf}\!\left(\tfrac{z}{\sqrt{2}}\right)\right) \end{aligned} \right.$$ $$P_{\text{outer}} = 1 - \Big(\Phi(z_2) - \Phi(z_1)\Big), \quad z_i = \frac{\text{x}_i - \mu}{\sigma}$$
計算例
標準正規分布で、\(x_1 = -1\)、\(x_2 = 1\)、\(\mu = 0\)、\(\sigma = 1\) とします。確率密度は $$f(-1) = f(1) = 0.398942 \times e^{-0.5} = 0.241971$$ です。\(\Phi(1) = 0.841345\)、\(\Phi(-1) = 0.158655\) なので、内側確率は $$0.841345 - 0.158655 = 0.682690$$ (約68.27%、おなじみの\(\pm 1\sigma\)の法則)、外側確率は \(0.317310\)(約31.73%)となります。
よくある質問
x1にx2より大きい値を入れたらどうなりますか? 内部で自動的に値が入れ替えられるため、内側の領域は常に「小さいほうの値」と「大きいほうの値」の間の区間になります。
\(\mu=0\)、\(\sigma=1\) は何を意味しますか? これは標準正規分布です。入力したxの値がそのままz値(zスコア)として読み取れます。
なぜf(x)が1を超えることがあるのですか? 確率密度は「確率そのもの」ではありません。\(\sigma\)が小さいとピークの高さが1を超えることがありますが、全体の面積は常に1のままです。