Công cụ này làm gì?
Công cụ này làm việc với phân phối chuẩn (Gauss) \(N(\mu, \sigma^2)\) được xác định bởi giá trị trung bình \(\mu\) và độ lệch chuẩn \(\sigma\). Với hai điểm x1 và x2 cho trước, máy tính trả về bốn con số: mật độ xác suất \(f(\text{x}_1)\) và \(f(\text{x}_2)\) tại mỗi điểm, xác suất tích lũy bên trong \(P(\text{x}_1 \le X \le \text{x}_2)\) (diện tích giữa hai điểm), và xác suất tích lũy bên ngoài ở hai đuôi, bằng 1 trừ đi phần diện tích bên trong. Đây là công cụ thống kê thuần toán học, không phụ thuộc quy định của bất kỳ quốc gia nào và dùng được ở mọi nơi.
Cách sử dụng
Nhập hai điểm x1 và x2 (máy tính tự động lấy giá trị nhỏ hơn làm cận dưới), sau đó nhập giá trị trung bình \(\mu\) và độ lệch chuẩn \(\sigma\). Giá trị mặc định \(\mu=0\) và \(\sigma=1\) cho ra phân phối chuẩn tắc, khi đó các giá trị x chính là điểm z (z-score). Độ lệch chuẩn bắt buộc phải lớn hơn 0.
Giải thích công thức
Mỗi điểm được chuyển thành điểm z theo $$z = \frac{x - \mu}{\sigma}.$$ Mật độ xác suất tính theo $$f(x) = \frac{1}{\sigma\sqrt{2\pi}}\; e^{-\frac{\left(x - \mu\right)^2}{2\,\sigma^2}}.$$ Diện tích tích lũy dùng hàm phân phối tích lũy chuẩn tắc CDF $$\Phi(z) = \tfrac{1}{2}\left(1 + \operatorname{erf}\!\left(\tfrac{z}{\sqrt{2}}\right)\right);$$ vì Java không có sẵn hàm erf nên công thức xấp xỉ Abramowitz & Stegun 7.1.26 (sai số khoảng 1e-7) được sử dụng. Xác suất bên trong là \(\Phi(z_2) - \Phi(z_1)\) và xác suất bên ngoài là 1 trừ đi giá trị đó.
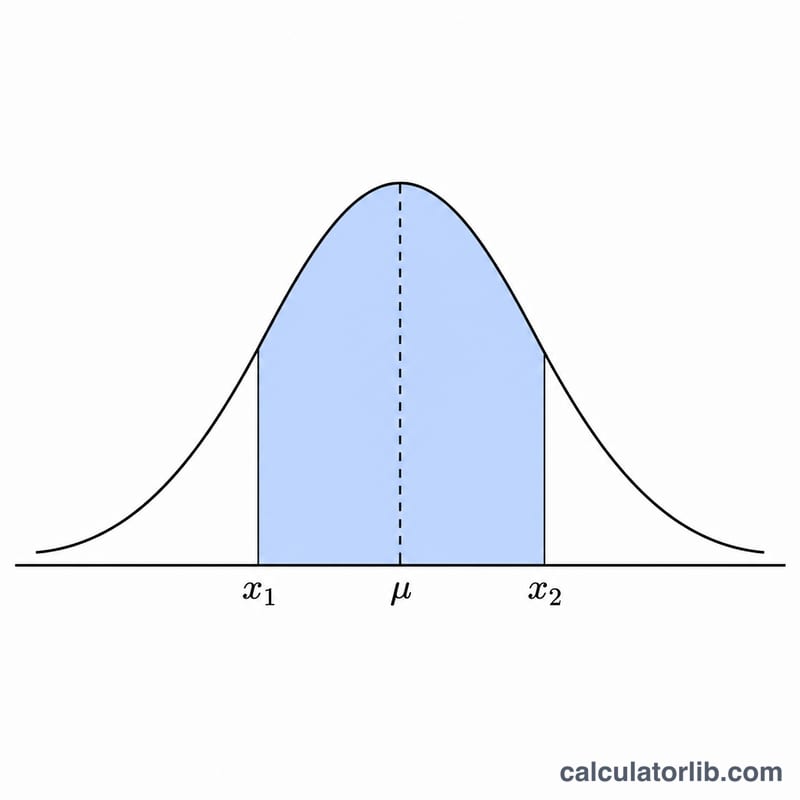
Ví dụ minh họa
Phân phối chuẩn tắc, với \(\text{x}_1 = -1\), \(\text{x}_2 = 1\), \(\mu = 0\), \(\sigma = 1\). Mật độ $$f(-1) = f(1) = 0.398942 \times e^{-0.5} = 0.241971.$$ \(\Phi(1) = 0.841345\) và \(\Phi(-1) = 0.158655\), nên xác suất bên trong là $$0.841345 - 0.158655 = 0.682690$$ (khoảng 68,27%, chính là quy tắc \(\pm 1\sigma\) quen thuộc) và xác suất bên ngoài là 0.317310 (khoảng 31,73%).
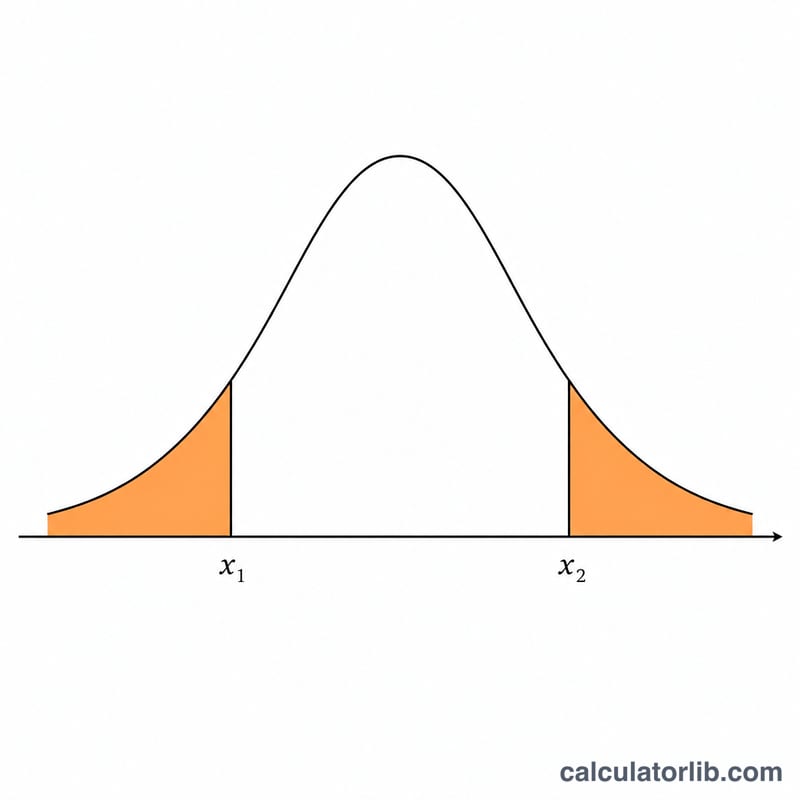
Câu hỏi thường gặp
Nếu tôi nhập x1 lớn hơn x2 thì sao? Hai giá trị sẽ được tự động hoán đổi bên trong, nên vùng bên trong luôn là khoảng nằm giữa giá trị nhỏ và giá trị lớn.
\(\mu=0\), \(\sigma=1\) nghĩa là gì? Đó là phân phối chuẩn tắc, nên các giá trị x của bạn được đọc trực tiếp như điểm z (z-score).
Tại sao đôi khi f(x) lớn hơn 1? Mật độ xác suất không phải là xác suất; khi \(\sigma\) nhỏ, chiều cao đỉnh có thể vượt quá 1 trong khi tổng diện tích vẫn bằng 1.