Bu hesaplayıcı ne işe yarar?
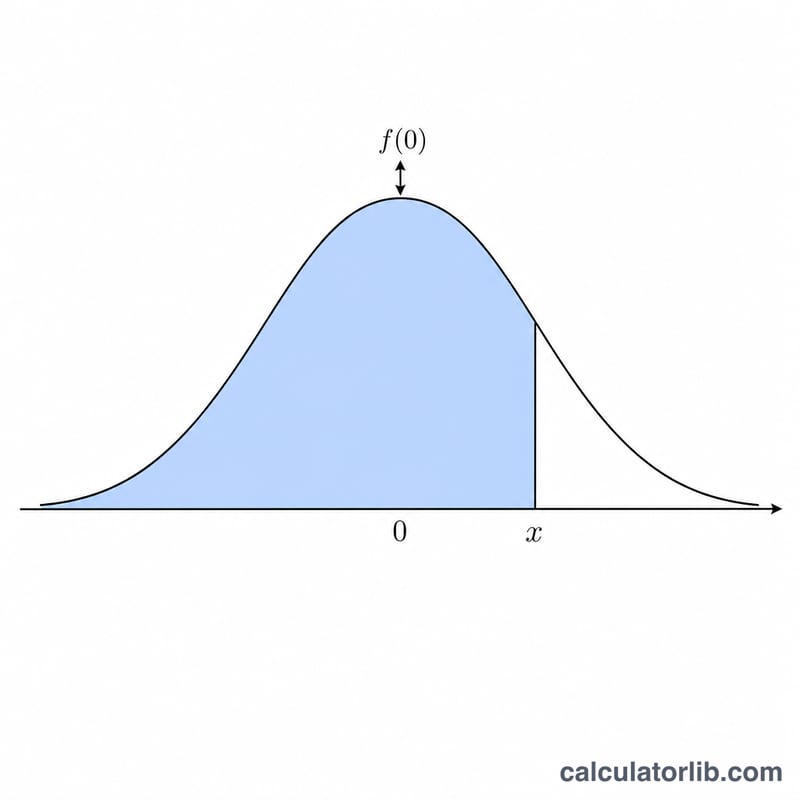
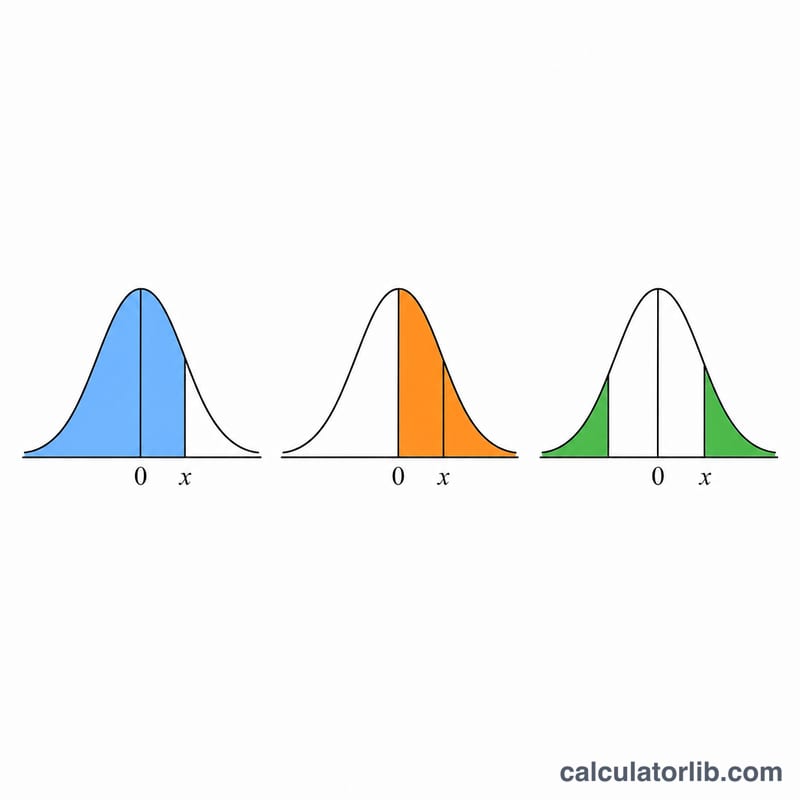
Standart normal dağılım N(0,1), ortalaması 0 ve standart sapması 1 olan çan eğrisidir. Bir x değeri (z-skoru olarak da bilinir) girdiğinizde, bu hesaplayıcı size dört sonuç döndürür: x noktasındaki olasılık yoğunluğu, alt kümülatif olasılık P(X ≤ x), üst kümülatif olasılık P(X ≥ x) ve iç çift taraflı olasılık P(−|x| ≤ X ≤ |x|). Pozitif, negatif veya sıfır olsun, her gerçek x değeriyle çalışır.
Nasıl kullanılır?
x için bir değer girin ve sonuçları okuyun. Örneğin x = 1, ortalamanın bir standart sapma üzerindeki noktaya karşılık gelir; x = 1.96 ise istatistikte klasik %95 güven sınırıdır. Standart normal değişken boyutsuz olduğundan araç herhangi bir birim gerektirmez.
Formüllerin açıklaması
Yoğunluk $$\varphi(x) = \frac{1}{\sqrt{2\pi}}\, e^{-x^{2}/2}$$ ile verilir; burada \(1/\sqrt{2\pi} \approx 0{,}3989423\)'tür. Alt kümülatif dağılım fonksiyonu, Gauss hata fonksiyonu erf kullanılarak $$\Phi(x) = \frac{1}{2}\left[\,1 + \operatorname{erf}\!\left(\frac{x}{\sqrt{2}}\right)\right]$$ biçiminde yazılır. Üst kuyruk \(Q(x) = 1 - \Phi(x)\), iç olasılık ise \(I(x) = \operatorname{erf}(|x|/\sqrt{2}) = 2\Phi(|x|) - 1\)'dir. Temel matematik kütüphanelerinde erf bulunmadığından, bunu Abramowitz & Stegun 7.1.26 rasyonel yaklaşımıyla (maksimum hata yaklaşık \(1{,}5\times10^{-7}\)) hesaplıyoruz; bu yaklaşım gösterim için yaklaşık altı ondalık basamağa kadar doğrudur.
Çözümlü örnek
x = 1 için: $$\varphi(1) = 0{,}3989423 \times e^{-0,5} \approx 0{,}2419707$$ \(\operatorname{erf}(0{,}7071068) \approx 0{,}6826895\) olduğundan \(\Phi(1) \approx 0{,}8413447\) çıkar; bu da \(0{,}1586553\)'lük bir üst kuyruk ve \(0{,}6826895\)'lik bir iç olasılık verir — yani bildiğimiz "değerlerin %68'i ±1 standart sapma içinde kalır" kuralı.
Sıkça sorulan sorular
Z-skoru nedir? Bir değerin ortalamadan kaç standart sapma uzakta olduğunu gösteren sayıdır. Standart normal dağılımda değerin kendisi ile z-skoru aynıdır.
İç olasılık neden |x| kullanır? Çift taraflı bölge sıfır etrafında simetriktir; bu nedenle negatif bir x, pozitif karşılığıyla aynı iç olasılığı verir.
Sonuçlar ne kadar doğru? Hata fonksiyonu yaklaşımı yaklaşık altı ondalık basamağa kadar doğrudur; bu da tipik istatistiksel çalışmalar için fazlasıyla yeterlidir.