Qu'est-ce que le calculateur du khi-deux ?
Cet outil calcule la statistique du khi-deux (χ²) dans le cadre d'un test d'ajustement. Le test du khi-deux mesure dans quelle mesure un ensemble de fréquences observées correspond aux fréquences que l'on attendrait sous une hypothèse donnée. Plus la valeur du χ² est élevée, plus l'écart entre les observations et les attentes est important. Il s'agit d'un outil statistique universel, utilisé en biologie, en marketing, en génétique, dans le contrôle qualité et dans les sciences sociales.
Comment l'utiliser
Saisissez vos valeurs observées (O) sous forme de liste séparée par des virgules, puis indiquez les valeurs attendues (E) correspondantes, dans le même ordre. Chaque paire représente une catégorie. Le calculateur renvoie la statistique du χ², le nombre de catégories utilisées et le nombre de degrés de liberté (le nombre de catégories moins un). Comparez votre χ² à une valeur critique issue d'une table de la loi du khi-deux, au seuil de signification de votre choix (par exemple 0,05), afin de décider si vous rejetez ou non l'hypothèse nulle.
La formule expliquée
La statistique du khi-deux se définit ainsi :
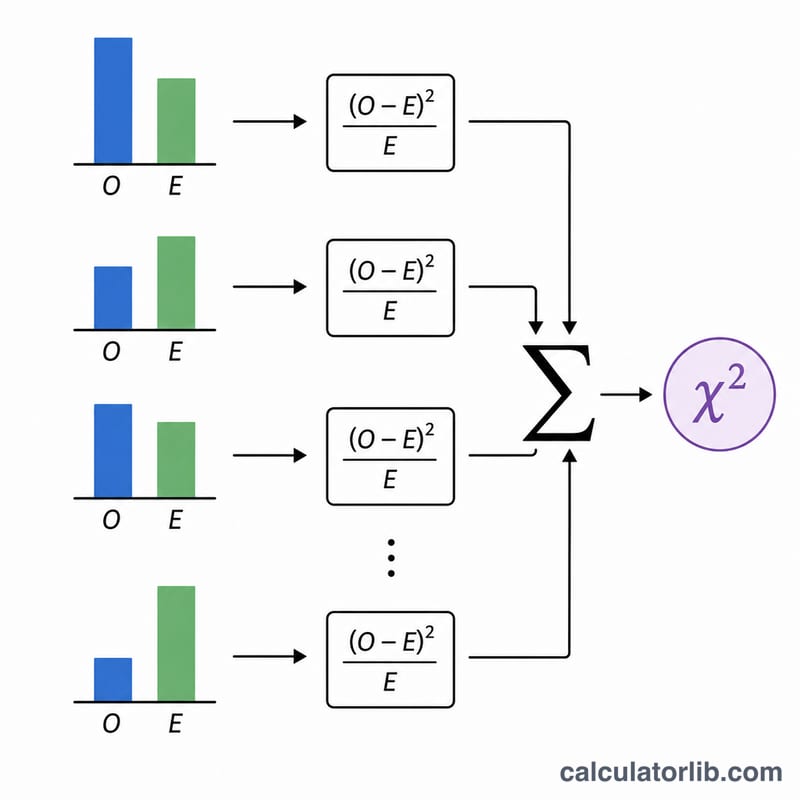
$$\chi^2 = \sum_{i=1}^{k} \frac{\left(O_i - E_i\right)^2}{E_i}$$
Pour chaque catégorie, soustrayez la valeur attendue de la valeur observée, élevez le résultat au carré, divisez par la valeur attendue, puis additionnez tous les termes. L'élévation au carré garantit que chaque contribution est positive et pénalise davantage les écarts importants.
Exemple concret
Imaginez que vous lanciez un dé en supposant que chaque face apparaît avec la même probabilité. Valeurs observées : 90, 60, 110, 40 et valeurs attendues : 80, 80, 80, 40. Les contributions sont \((90-80)^2/80 = 1{,}25\), \((60-80)^2/80 = 5\), \((110-80)^2/80 = 11{,}25\) et \((40-40)^2/40 = 0\). La somme donne \(\chi^2 = 17{,}5\) avec 3 degrés de liberté.
Questions fréquentes
Que sont les degrés de liberté ? Pour un test d'ajustement, \(df = k - 1\) (nombre de catégories − 1).
Que signifie un χ² élevé ? Une valeur plus élevée indique que les données observées s'écartent davantage des valeurs attendues, ce qui suggère que l'hypothèse pourrait ne pas convenir.
Les valeurs attendues peuvent-elles être nulles ? Non : diviser par une fréquence attendue égale à zéro n'a pas de sens, ces catégories sont donc ignorées.