什麼是冪次迴歸?
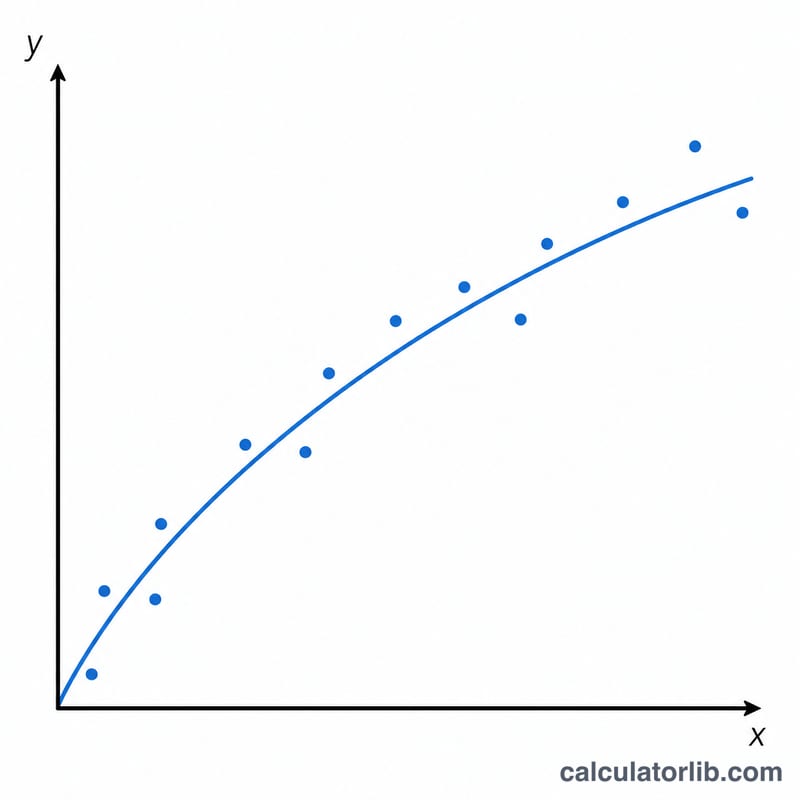
冪次迴歸(Power Regression)是把模型 \(y = A \cdot x^{B}\) 套用到一組資料點上的方法。每當某個量會隨另一個量以「次方」方式變化時,就會出現這種曲線,在物理、生物與經濟領域都相當常見——例如異速生長(allometric growth)、學習曲線,以及各式各樣的尺度律(scaling law)。其中指數 \(B\) 代表變化的尺度速率,而係數 \(A\) 則決定了整體的大小規模。
如何使用這個計算器
請以逗號或空格分隔的方式輸入你的 X 值與 Y 值,兩者依位置一一對應(第一個 X 對應第一個 Y,以此類推)。由於計算過程會用到自然對數,所有數值都必須為嚴格正數;任何含有零或負值的資料列都會被自動略過。接著選擇要顯示的有效位數,即可讀取算出的係數與相關係數 \(r\)。
公式說明
關鍵在於「線性化」。對 \(y = A \cdot x^{B}\) 兩邊取自然對數,可得 \(\ln y = \ln A + B \cdot \ln x\),這在轉換後的變數 \(t = \ln x\) 與 \(u = \ln y\) 下就是一條直線。接著我們對它執行一般最小平方迴歸:先計算各自的平均值,再求平方和 \(S_{xx}\)、\(S_{yy}\) 以及交叉乘積 \(S_{xy}\)。斜率 \(B = S_{xy}/S_{xx}\) 就是指數,而 \(A = \exp(\overline{\ln y} - B \cdot \overline{\ln x})\)。相關係數 \(r = S_{xy}/\sqrt{S_{xx} \cdot S_{yy}}\) 則衡量對數轉換後的資料點排成一直線的程度。
$$ y = A \cdot x^{B} $$ $$ \text{where}\quad \left\{ \begin{aligned} B &= \frac{n\sum \ln x_i \ln y_i - \sum \ln x_i \sum \ln y_i}{n\sum (\ln x_i)^2 - \left(\sum \ln x_i\right)^2} \\ A &= \exp\!\left( \overline{\ln y} - B\,\overline{\ln x} \right) \\ x_i &= \text{X values},\quad y_i = \text{Y values} \end{aligned} \right. $$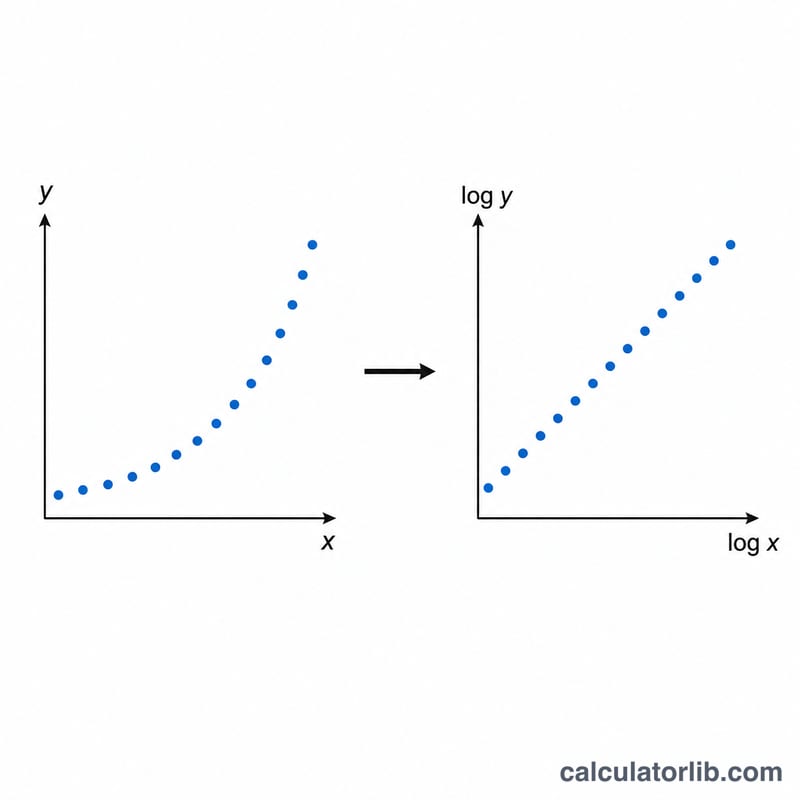
實際範例
以資料 (1,2)、(2,5)、(3,11)、(4,21)、(5,33)(\(n = 5\))為例,取對數後的各項總和為 \(S_{xx} \approx 1.6155\)、\(S_{xy} \approx 2.8340\)、\(S_{yy} \approx 5.0410\)。於是 \(B = 2.8340/1.6155 \approx 1.7544\),\(A = \exp(2.2483 - 1.7544 \cdot 0.9575) \approx 1.7655\)。相關係數 \(r \approx 0.9933\),屬於非常良好的擬合。最終模型為 \(y \approx 1.7655 \cdot x^{1.7544}\)。
常見問題
為什麼所有數值都必須是正數?本方法會計算 \(\ln(x)\) 與 \(\ln(y)\),而零或負數的對數沒有定義,因此非正數的資料點無法使用。
該如何解讀相關係數 r?\(|r|\) 大於 0.7 表示強相關,0.4–0.7 為中度相關,0.2–0.4 為弱相關,低於 0.2 則幾乎沒有關聯。
用自然對數還是常用對數(以 10 為底)會有差別嗎?不會——無論用哪一種,指數 \(B\) 與相關係數 \(r\) 都完全相同。本工具一律使用自然對數,並以 \(\exp()\) 一致地計算 \(A\),因此結果會與標準參考文獻相符。