이 계산기로 할 수 있는 일
이 기술통계 계산기는 입력한 숫자 목록을 수학, 과학, 데이터 분석에서 자주 쓰는 핵심 지표로 요약해 줍니다. 최솟값, 최댓값, 범위, 개수, 합계, 평균, 중앙값, 최빈값, 분산, 표준편차를 한 번에 보여 줍니다. 스프레드시트 열에서 복사한 값을 그대로 붙여넣거나 직접 입력하면 모든 요약 통계가 즉시 계산됩니다. 순수하게 수학적이고 단위에 종속되지 않으므로, 특정 국가의 규칙 없이 어디서나 동일하게 작동합니다.
사용 방법
텍스트 상자에 데이터를 입력하되 값 사이를 쉼표, 공백, 탭, 줄바꿈으로 구분하세요. 스프레드시트 열에서 복사한 데이터는 바로 붙여넣어도 됩니다. 입력한 숫자가 더 큰 집단에서 뽑은 일부인 표본(Sample)인지, 전체인 모집단(Population)인지 선택하세요. 이 선택은 분산과 표준편차에만 영향을 줍니다. 표본은 편차 제곱합을 \(n-1\)로 나누고(베셀 보정), 모집단은 \(n\)으로 나눕니다. 나머지 통계는 두 경우 모두 동일합니다.
공식 설명
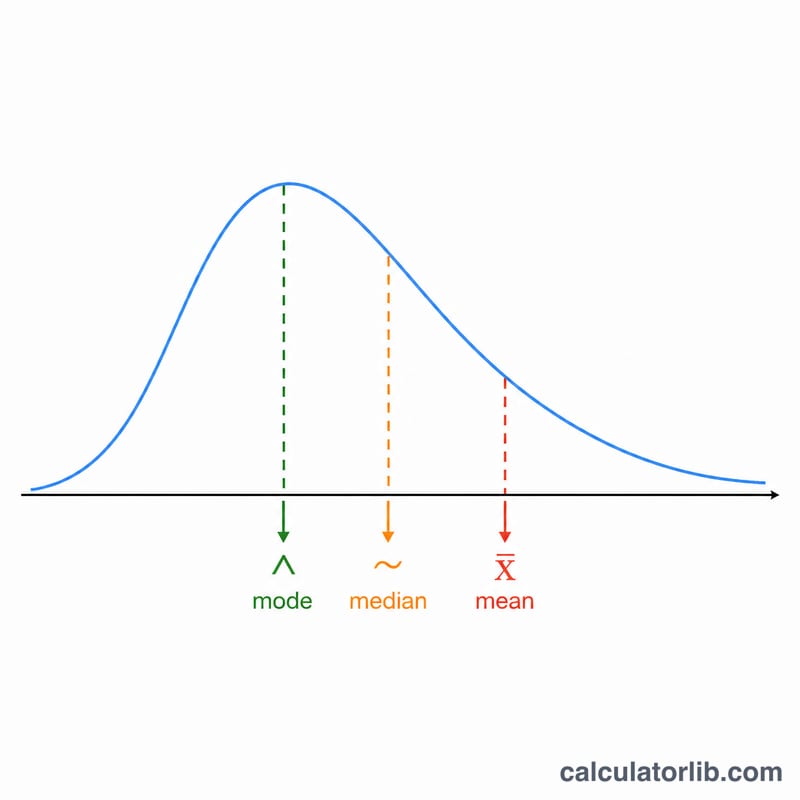
평균은 모든 값의 합을 개수 \(n\)으로 나눈 값입니다. 중앙값은 데이터를 정렬했을 때 가운데 오는 값이며(개수가 짝수이면 가운데 두 값의 평균), 최빈값은 가장 자주 나타나는 값입니다. 여러 값이 같은 빈도로 동률이면 다봉형(multimodal)이고, 반복되는 값이 없으면 최빈값은 존재하지 않습니다. 분산은 평균으로부터 떨어진 거리의 제곱 평균으로 흩어진 정도를 나타내며, 표준편차는 그 제곱근으로 원래 단위로 돌아갑니다.
표본의 경우:
$$\bar{x} = \frac{1}{n}\sum_{i=1}^{n} x_i \qquad s^{2} = \frac{1}{n-1}\sum_{i=1}^{n}\left(x_i - \bar{x}\right)^{2} \qquad s = \sqrt{s^{2}}$$모집단의 경우:
$$\mu = \frac{1}{n}\sum_{i=1}^{n} x_i \qquad \sigma^{2} = \frac{1}{n}\sum_{i=1}^{n}\left(x_i - \mu\right)^{2} \qquad \sigma = \sqrt{\sigma^{2}}$$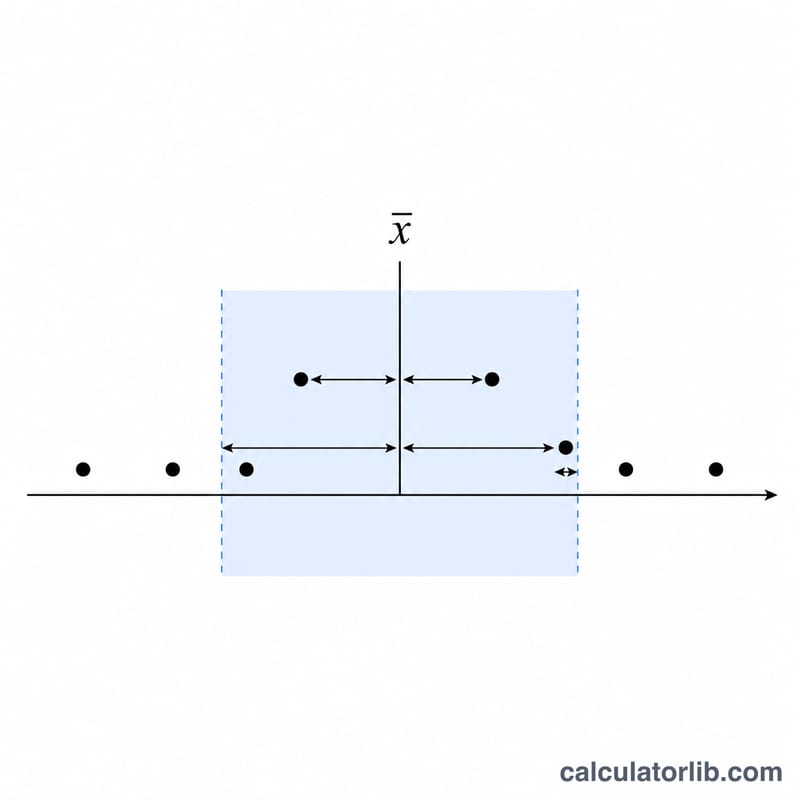
계산 예시
표본 10, 2, 38, 23, 38, 23, 21의 경우: \(n = 7\), 최솟값 = 2, 최댓값 = 38, 범위 = 36, 합계 = 155, 평균 = 22.142857, 중앙값 = 23, 최빈값 = 23과 38(이봉형)입니다. 편차 제곱합은 1058.857이므로 표본 분산 \(= 1058.857 / 6 = 176.4762\), 표본 표준편차 = 13.2844가 됩니다. 만약 모집단으로 본다면 분산 = 151.2653, 표준편차 = 12.2990입니다.
자주 묻는 질문
표본과 모집단 중 무엇을 선택해야 하나요? 데이터가 더 큰 집단을 추정하기 위한 일부라면 표본(Sample)을, 모든 구성원을 빠짐없이 가지고 있다면 모집단(Population)을 선택하세요.
표준편차가 N/A로 나오는 이유는? 값이 하나뿐이면 표본의 분모 \(n-1 = 0\)이 되어 표본 분산을 정의할 수 없습니다. 값을 최소 두 개 이상 입력해 주세요.
음수나 소수도 입력할 수 있나요? 네. 음수, 소수, 지수 표기(과학적 표기)를 모두 인식하며, 빈 줄이나 불필요한 구분자는 자동으로 무시합니다.