이 계산기로 할 수 있는 것
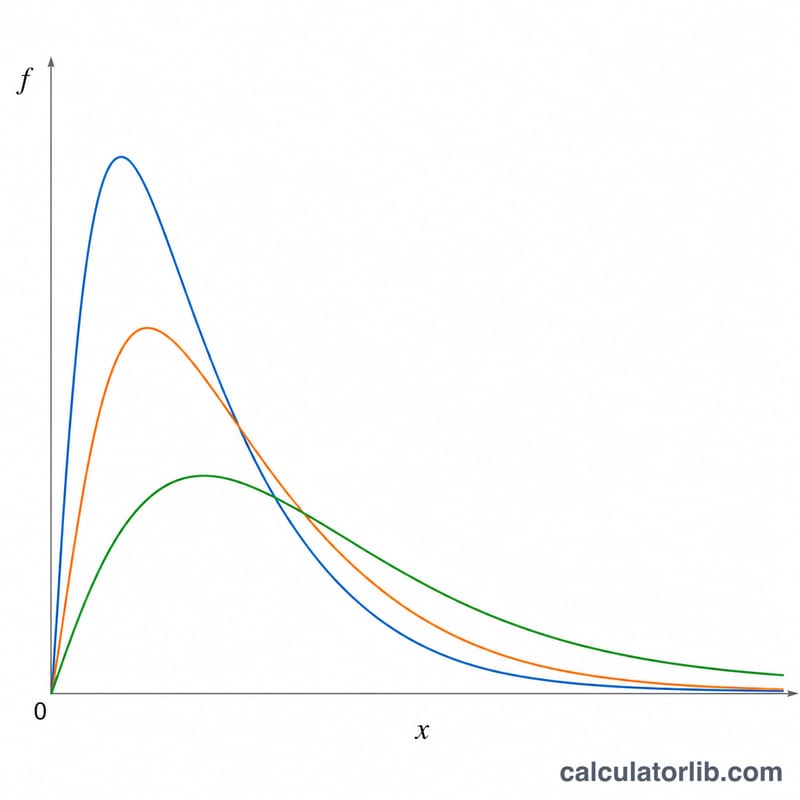
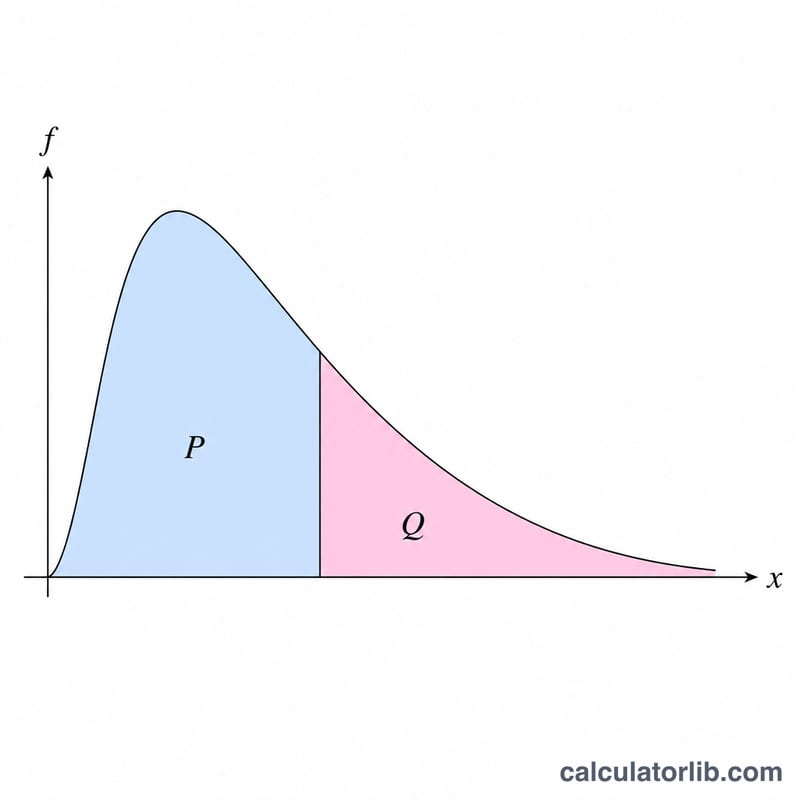
F분포는 두 분산을 비교할 때 등장합니다. 예를 들어 분산분석(ANOVA), 회귀분석의 전체 유의성 검정, 두 분산이 같은지 확인하는 F검정이 대표적입니다. 이 도구는 분자 자유도 \(v_1\)과 분모 자유도 \(v_2\)를 가진 F분포를 여러 \(x\) 값에 걸쳐 한 번에 계산해, 표와 그래프를 동시에 만들어 줍니다. 세 가지 함수 중 하나를 선택할 수 있습니다. 확률밀도 \(f\), 하측 누적확률 \(P\)(누적분포함수 CDF), 그리고 상측 누적확률 \(Q\)(생존함수)입니다. 특히 \(Q\)는 우측 꼬리 p값을 구할 때 유용합니다.
사용 방법
먼저 원하는 함수를 선택하세요. 두 자유도를 입력합니다(둘 다 0보다 커야 합니다). 그다음 계산할 구간을 설정합니다. \(x\)의 시작값(\(x\)는 0 이상이어야 합니다), 점 사이의 증가량, 반복 횟수를 차례로 지정하세요. 계산기는 \(i = 0\)부터 \(\text{loopCount}-1\)까지 $$x_i = \text{initialX} + i \times \text{stepX}$$ 로 \(x\) 값을 만들고, 각 지점에서 선택한 함수 값을 출력합니다. 기본 설정(\(v_1 = 3\), \(v_2 = 5\), 시작 0, 간격 0.1, 51개 점)은 \(x\)를 0부터 5까지 훑습니다.
공식 풀이
확률밀도는 베타 함수 \(B(a,b) = \dfrac{\Gamma(a)\Gamma(b)}{\Gamma(a+b)}\)를 사용합니다. 자유도가 클 때도 수치적으로 안정적으로 계산하기 위해, 로그 감마 함수를 활용해 로그 단위로 처리합니다.
$$f(x) = \frac{\sqrt{\dfrac{(\nu_1 x)^{\nu_1}\,\nu_2^{\nu_2}}{(\nu_1 x + \nu_2)^{\nu_1+\nu_2}}}}{x\,B\!\left(\tfrac{\nu_1}{2},\tfrac{\nu_2}{2}\right)}$$
누적확률은 깔끔한 닫힌 형태를 가집니다. \(P(x)\)는 정규화된 불완전 베타 함수 \(I_z\!\left(\tfrac{\nu_1}{2}, \tfrac{\nu_2}{2}\right)\)와 같으며, 여기서 \(z = \dfrac{\nu_1 x}{\nu_1 x + \nu_2}\)입니다.
$$F(x) = I_{\,z}\!\left(\tfrac{\nu_1}{2},\,\tfrac{\nu_2}{2}\right),\quad z = \frac{\nu_1 x}{\nu_1 x + \nu_2}$$
상측 꼬리는 단순히 \(Q(x) = 1 - P(x)\)로 구합니다. 불완전 베타 함수는 표준적인 연분수 방법으로 계산합니다.
계산 예시
\(v_1 = 3\), \(v_2 = 5\)이고 \(x = 1\)일 때를 보겠습니다. 상수 $$C = \frac{3^{1.5} \times 5^{2.5}}{B(1.5,\, 2.5)} = \frac{5.196152 \times 55.901699}{0.196350} = 1479.36$$입니다. 따라서 $$f = \frac{1479.36 \times 1^{0.5}}{(5 + 3)^4} = \frac{1479.36}{4096} = 0.36117$$이 됩니다. 누적분포함수의 경우 \(z = \tfrac{3}{8} = 0.375\)이므로 \(P = I_{0.375}(1.5,\, 2.5) = 0.5351\), 따라서 \(Q = 0.4649\)입니다.
자주 묻는 질문
왜 \(x = 0\)에서 확률밀도가 발산하나요? \(v_1 < 2\)일 때는 \(x = 0\)에서 확률밀도가 무한대로 발산합니다. \(v_1 = 2\)이면 값이 1이고, \(v_1 > 2\)이면 0이 됩니다.
\(x\)는 어느 범위가 적절한가요? F 변수는 음수가 될 수 없으므로 \(x = 0\)에서 시작해, 분포의 대부분을 담을 수 있을 만큼 우측 꼬리까지 충분히(보통 \(x\)를 5~10까지) 늘리는 것이 좋습니다.
평균은 항상 존재하나요? 평균 \(\dfrac{v_2}{v_2-2}\)는 \(v_2 > 2\)일 때만, 분산은 \(v_2 > 4\)일 때만 존재합니다. 다만 이 계산기에서 함수 값을 구하는 데는 둘 다 필요하지 않습니다.