로그정규분포란?
양의 확률변수 X의 자연로그 ln(X)가 정규분포를 따를 때, X는 로그정규분포를 따른다고 합니다. 즉 X = e^Y이고, 여기서 Y는 평균이 μ, 표준편차가 σ인 정규분포를 따르죠. 로그는 양수에서만 정의되기 때문에 로그정규분포는 양의 실수 영역 전체에 분포합니다. 그래서 음수가 될 수 없는 값을 모델링하기에 안성맞춤입니다. 주가, 소득, 입자 크기, 생체 측정값, 고장까지 걸리는 시간(수명 데이터) 등이 대표적인 예입니다.
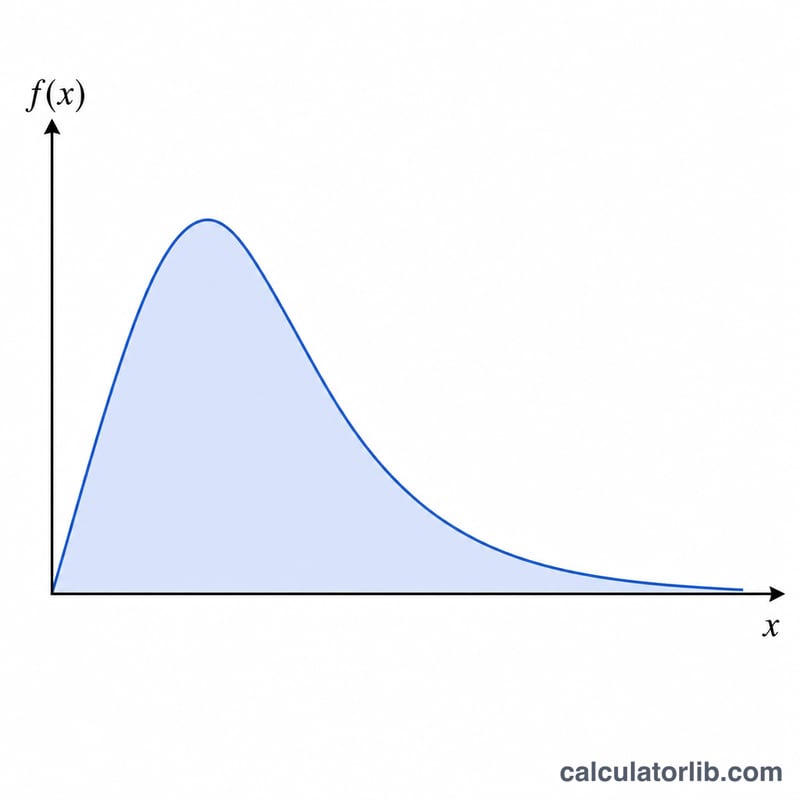
계산기 사용법
먼저 분포를 평가하고 싶은 값 \(x\)를 입력합니다(반드시 0보다 커야 합니다). 그다음 \(\mu\)와 \(\sigma\)를 입력하세요. 초보자가 가장 많이 헷갈리는 부분이 바로 이 점인데, 여기서 \(\mu\)와 \(\sigma\)는 X가 아니라 ln(X)의 평균과 표준편차입니다. 계산 결과로는 세 가지 값이 나옵니다. 확률밀도 \(f(x)\), 하측 누적확률 \(P(x) = P(X \le x)\), 그리고 상측 누적확률 \(Q(x) = P(X > x) = 1 - P(x)\)입니다.
공식 풀이
표준화 점수를 \(z = (\ln x - \mu) / \sigma\)로 정의합니다. 확률밀도는
$$f(x) = \frac{1}{\text{x}\;\sigma\sqrt{2\pi}}\,\exp\!\left(-\frac{\left(\ln \text{x} - \mu\right)^2}{2\,\sigma^2}\right)$$입니다. 하측 누적확률은
$$\begin{gathered} P(X \le x) = \Phi\!\left(\frac{\ln \text{x} - \mu}{\sigma}\right) \\[1.5em] \text{where}\quad \left\{ \begin{aligned} \Phi(z) &= \tfrac{1}{2}\left(1 + \operatorname{erf}\!\left(\tfrac{z}{\sqrt{2}}\right)\right) \\ P(X > x) &= 1 - P(X \le x) \end{aligned} \right. \end{gathered}$$이며, 여기서 \(\Phi\)는 표준정규분포의 누적분포함수로 \(\Phi(z) = 0.5 \cdot (1 + \operatorname{erf}(z/\sqrt{2}))\)로 표현됩니다. erf 함수는 일반적인 수학 라이브러리에 기본 내장되어 있지 않기 때문에, 이 계산기는 오차가 약 \(1.5 \times 10^{-7}\) 수준으로 정확한 Abramowitz & Stegun 7.1.26 다항식 근사를 사용합니다.
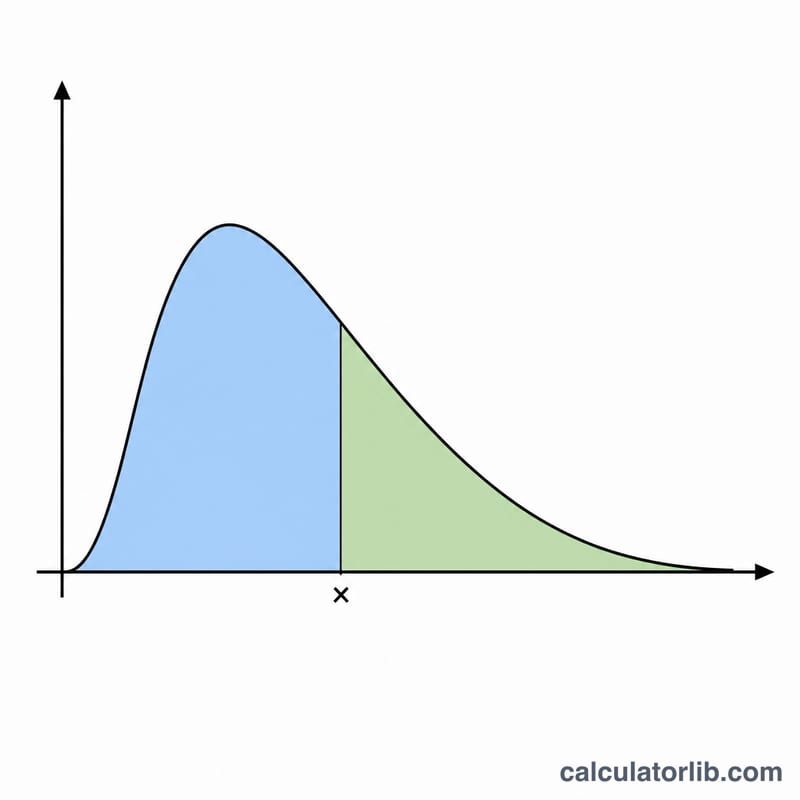
계산 예시
\(x = 2\), \(\mu = 0\), \(\sigma = 1\)을 넣어보겠습니다. \(\ln(2) = 0.693147\)이므로 \(z = 0.693147\)이 됩니다. 확률밀도는 exp 항 \(0.786429\)를 \(5.013256\)으로 나눈 값, 즉 약 \(0.156874\)입니다. 하측 누적확률은 \(\Phi(0.693147) \approx 0.755891\)이므로, 상측 누적확률은 \(Q(2) = 1 - 0.755891 \approx 0.244109\)가 됩니다.
자주 묻는 질문
왜 x는 양수여야 하나요? \(\ln(x)\)는 x가 양수일 때만 정의되므로, 로그정규분포 역시 \(x > 0\)에서만 정의됩니다. \(x \le 0\)이면 확률밀도는 0, \(P(x) = 0\), \(Q(x) = 1\)입니다.
X 자체의 평균은 어떻게 구하나요? X의 평균은 \(\exp(\mu + \sigma^2/2)\), 중앙값은 \(\exp(\mu)\), 최빈값은 \(\exp(\mu - \sigma^2)\)입니다. 이 값들은 ln(X)를 설명하는 \(\mu\), \(\sigma\)와는 다르다는 점에 유의하세요.
σ가 0이면 어떻게 되나요? 표준편차가 0이면 분포가 한 점에 몰리는 퇴화된 형태가 되고 0으로 나누는 문제가 생기므로 입력이 거부됩니다. 대신 아주 작은 양수 값을 \(\sigma\)로 사용하세요.