이 계산기의 기능
이 도구는 포아송 분포의 백분위 점을 계산합니다. 평균(\(\lambda\))과 목표 누적확률을 입력하면, 해당 확률에 대응하는 정수 사건 수 \(x\)를 돌려줍니다. 포아송 누적분포함수(CDF)의 역연산에 해당하며, 하측 누적 P와 상측 누적 Q 두 가지 방식으로 동작합니다.
사용 방법
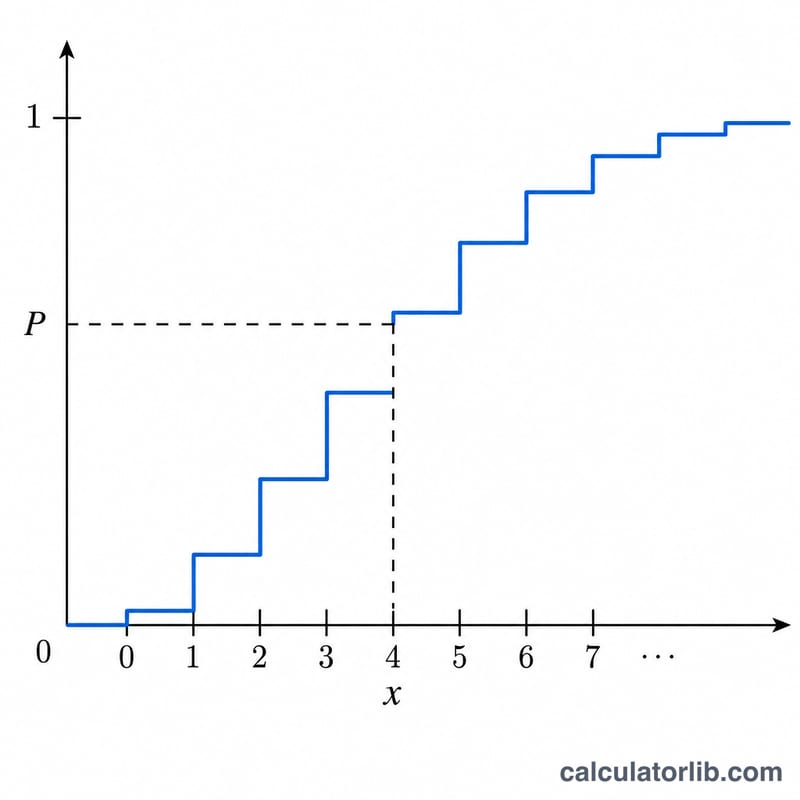
먼저 누적 방식을 선택하세요. 하측 누적 P 방식에서는 목표 하측 확률 P를 입력하면, \(P(x, \lambda) \ge P\)를 만족하는 가장 작은 정수 \(x\)를 반환합니다. $$x^{*} = \min\left\{\, x \in \mathbb{Z}_{\ge 0} : \sum_{k=0}^{x} \frac{e^{-\lambda}\,\lambda^{k}}{k!} \ge \text{p} \,\right\}, \quad \lambda = \text{Mean } \lambda$$ 상측 누적 Q 방식에서는 상측 확률 Q를 입력하면, 본 사이트의 \(x\) 포함 규약인 \(Q(x) = 1 - P(x-1)\)을 사용해 \(Q(x, \lambda) \ge Q\)를 만족하는 가장 큰 \(x\)를 반환합니다. $$x^{*} = \max\left\{\, x \in \mathbb{Z}_{\ge 0} : 1 - \sum_{k=0}^{x-1} \frac{e^{-\lambda}\,\lambda^{k}}{k!} \ge \text{p} \,\right\}, \quad \lambda = \text{Mean } \lambda$$ 그다음 평균 \(\lambda\)(기대되는 사건 발생 횟수)를 입력하세요. 모든 입력값은 단위가 없는 무차원 값입니다.
공식 설명
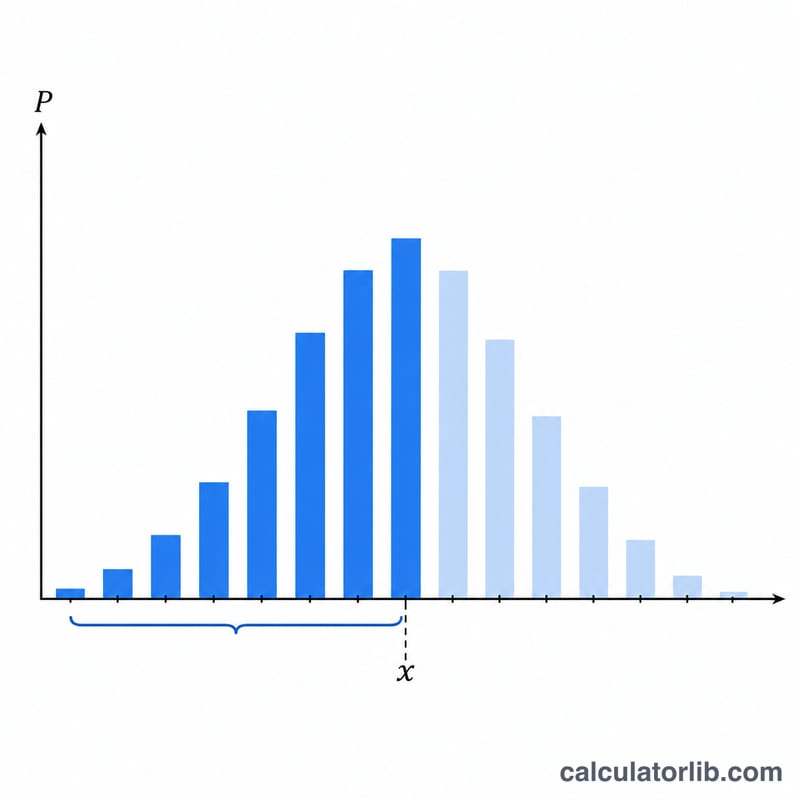
확률질량함수는 \(f(t, \lambda) = e^{-\lambda} \cdot \lambda^{t} / t!\) 입니다. 수치 안정성을 위해 각 항은 반복적으로 계산합니다. \(\text{term}(0) = e^{-\lambda}\)이고 \(\text{term}(t) = \text{term}(t-1) \cdot \lambda / t\) 이며, 이렇게 하면 \(\lambda^{t}\)와 \(t!\)에서 발생하는 오버플로를 피할 수 있습니다. 하측 누적값은 이 항들의 누적 합이고, 상측 누적값은 하측 누적값을 한 인덱스 밀어 1에서 뺀 값입니다.
계산 예시
하측 방식에서 \(P = 0.3\), \(\lambda = 5\)인 경우, 누적값은 차례로 \(P(0)=0.0067\), \(P(1)=0.0404\), \(P(2)=0.1247\), \(P(3)=0.2650\), \(P(4)=0.4405\) 이 됩니다. 처음으로 \(0.3\)에 도달하는 \(x\)는 \(x = 4\) 입니다. 상측 방식에서 \(Q = 0.3\), \(\lambda = 5\)인 경우 \(Q(6)=0.384\), \(Q(7)=0.238\) 이므로, \(Q \ge 0.3\)을 만족하는 가장 큰 \(x\)는 \(x = 6\) 입니다.
자주 묻는 질문
상측 방식에서는 왜 합에 x를 포함하나요? 본 사이트는 \(Q(x)\)를 \(t = x\)부터 무한대까지의 합, 즉 \(Q(x) = 1 - P(x-1)\)로 정의합니다. 이는 흔히 쓰이는 \(P(X > x)\) 규약과 다릅니다.
\(\lambda = 0\)이면 어떻게 되나요? 모든 확률 질량이 \(t = 0\)에 모이므로, 하측 백분위수는 0이고 \(x \ge 1\)인 모든 \(x\)에 대해 \(Q(x)=0\) 입니다.
0에서 1 범위를 벗어난 확률을 입력하면요? 계산기가 유효하지 않은 입력으로 표시합니다. 확률은 반드시 \(0 \le P, Q \le 1\)을 만족해야 하며 \(\lambda \ge 0\) 이어야 합니다.