這個計算機能做什麼
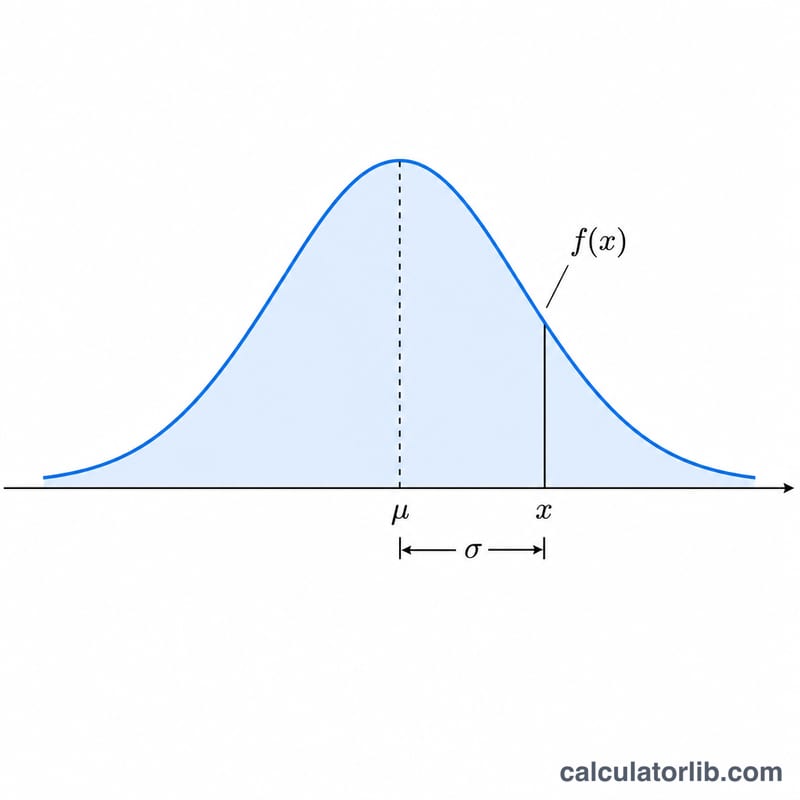
常態分布計算機可在你指定的點 \(x\) 上,依給定的平均數(\(\mu\))與標準差(\(\sigma\))評估一個常態分布變數。它會回傳三個核心數值:機率密度 \(f(x)\)、左尾累積機率 \(P(X \le x)\),以及右尾累積機率 \(P(X > x)\)。這是一個通用的數學與統計工具,不涉及任何特定國家的假設或規定。若採用預設值 \(\mu = 0\) 與 \(\sigma = 1\),它就會以標準常態分布來計算。
使用方式
輸入你想評估分布的數值 \(x\)、平均數 \(\mu\),以及標準差 \(\sigma\)(必須大於 0)。計算機會先以 $$z = \frac{x - \mu}{\sigma}$$ 將數值標準化,接著計算機率密度與左右兩側的累積機率。左尾累積機率是曲線下方、\(x\) 左側的面積;右尾累積機率則是 \(x\) 右側的面積,兩者相加恆為 1。
公式說明
機率密度為 $$f(x) = \frac{1}{\sigma\sqrt{2\pi}}\, e^{-\frac{\left(x - \mu\right)^2}{2\,\sigma^2}}$$ 左尾累積機率即累積分布函數 $$\Phi(z) = \frac{1}{2}\left[1 + \operatorname{erf}\!\left(\frac{z}{\sqrt{2}}\right)\right]$$ 其中 \(\operatorname{erf}\) 為高斯誤差函數。由於標準數學函式庫並未內建 \(\operatorname{erf}\),本工具採用 Abramowitz & Stegun 7.1.26 的有理近似式,精度約達 1e-7。右尾累積機率則單純為 \(1 - \Phi(z)\)。
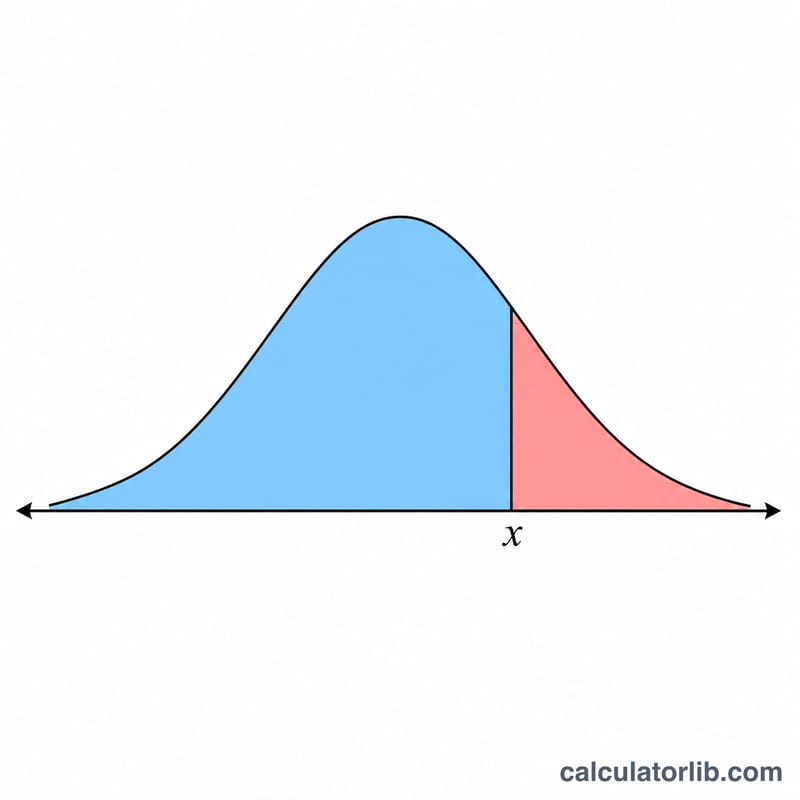
實際範例
以類似 IQ 的分布為例,設 \(\mu = 100\)、\(\sigma = 15\),並在 \(x = 130\) 處評估。首先 $$z = \frac{130 - 100}{15} = 2$$ 機率密度為 $$f(130) = \frac{0.3989422804}{15} \times e^{-2} = 0.003599750$$ 左尾累積機率 \(\Phi(2) = 0.9772498681\),因此右尾累積機率為 \(0.0227501319\),代表約有 2.28% 的數值超過 130。
常見問題
\(z\) 是什麼?\(z\) 是標準化分數,表示 \(x\) 高於(正值)或低於(負值)平均數多少個標準差。
為什麼 \(\sigma\) 必須是正數?標準差若為零或負數,分布便無法定義,且會造成除以零的錯誤,因此 \(\sigma\) 必須大於 0。
\(f(x)\) 與兩個機率相加會等於 1 嗎?相加等於 1 的是兩個累積機率 \(P(X \le x)\) 與 \(P(X > x)\)。機率密度 \(f(x)\) 並非機率,也不屬於這個總和;它代表的是曲線在 \(x\) 點的高度。